结合网络大牛的总结(致谢大牛!),目前存在一些针对BERT进行优化的衍生模型。
主要优化方向:
性能(ALBERT)
增加图谱实体(ERINE, K-BERT)
多样的Attention方式(XLNet, UNILM)
新增训练任务(MT-DNN)
兼容生成式任务(MASS, UNILM)等
ALBERT
Ref: ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
轻量级BERT模型(减少参数量、但未减少计算量):
跨层共享参数(Attention层共享、全连接层共享)
修改预测句子衔接的任务:负样本由“随机两个句子”改为“颠倒正样本的两个句子”
拆分Embedding向量维度和隐藏层向量维度,将Evm=Avk * Bkm
ERNIE
Ref: ERNIE: Enhanced Representation through Knowledge Integration
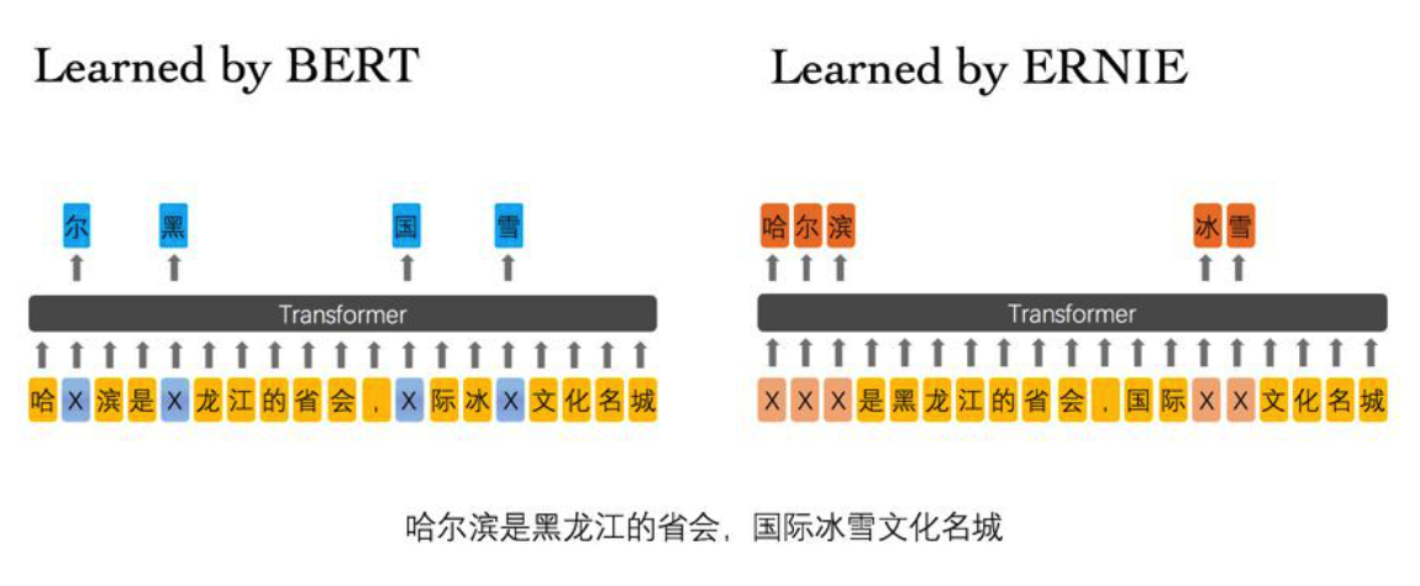
为百度开发模型,与BERT的主要差别是,在做mask任务时,mask的为一个实体,而非一个词。
MT-DNN
Ref: Multi-Task Deep Neural Networks for Natural Language Understanding
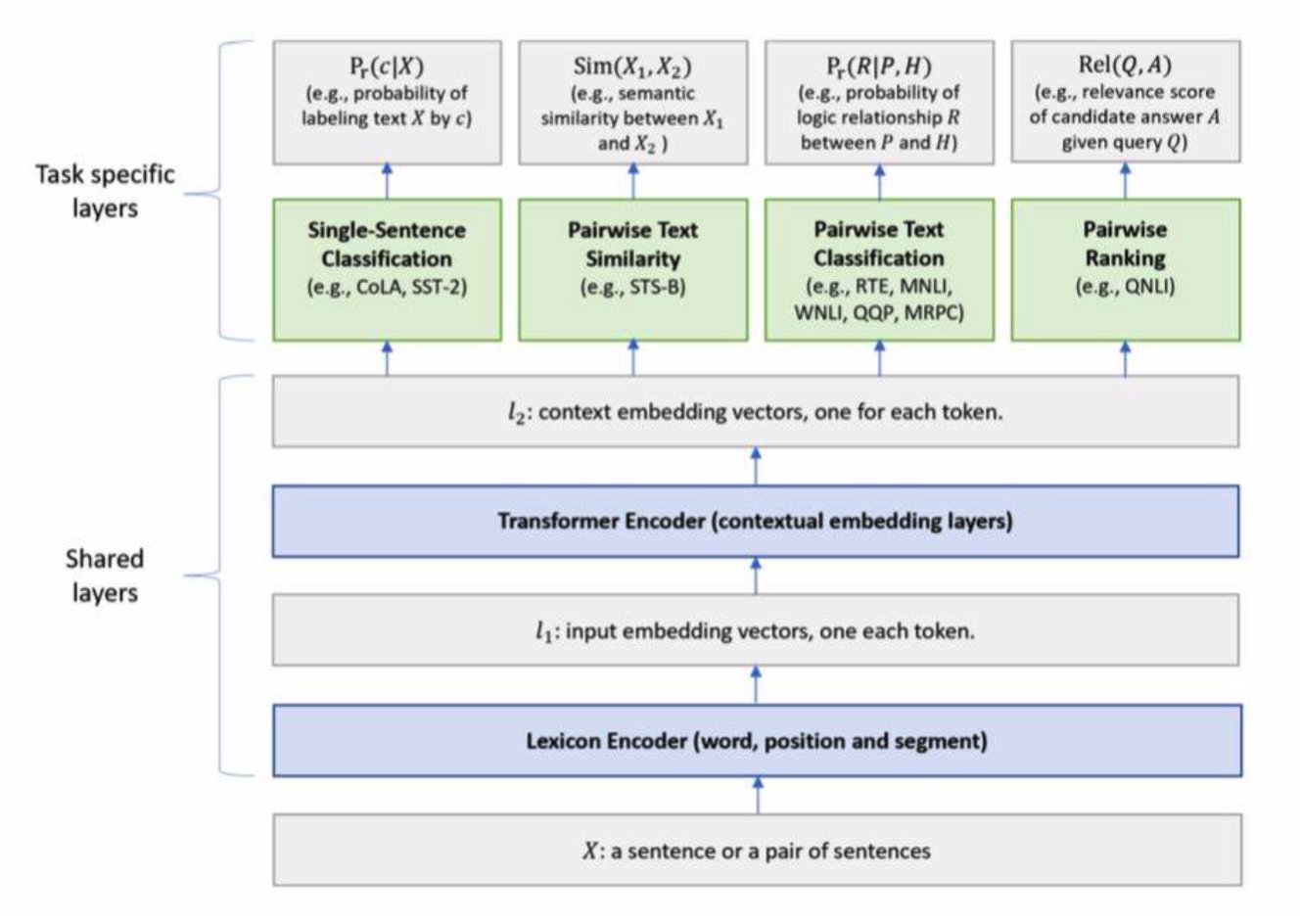
为微软开发模型,与BERT的主要区别是,额外增加了自定义的multi-task进行训练。
XLNet
Ref: XLNet:Generalized Autoregressive Pretraining for Language Understanding
主要特点
在自回归LM模式下,采用掩码双流自注意力(Masked Two-Stream Self-Attention),实现双向语言模型
引入了Transformer-XL的主要思路:相对位置编码(relative encoding scheme)以及分段递归机制(segment recurrence mechanism),有利于长文档任务
加大增加了预训练阶段使用的数据规模
出发点
1)融合自回归LM和DAE LM两者的优点。
如果站在自回归LM的角度,如何引入和双向语言模型等价的效果?
如果站在DAE LM的角度看,它本身是融入双向语言模型的,如何抛掉表面的那个[Mask]标记,让预训练和Fine-tuning保持一致?
2)Bert被Mask单词之间相互独立的问题
Bert 在第一个预训练阶段,假设句子中多个单词被Mask掉,这些被Mask掉的单词之间没有任何关系,是条件独立的,而有时候这些单词之间是有关系的,XLNet则考虑了这种关系。
解决方法
1)排序语言模型
XLNet通过对句子中单词的排列组合,把一部分Ti下文的单词排到Ti的上文位置中,于是,就看到了上文和下文,但是形式上看上去仍然是从左到右在预测后一个单词。
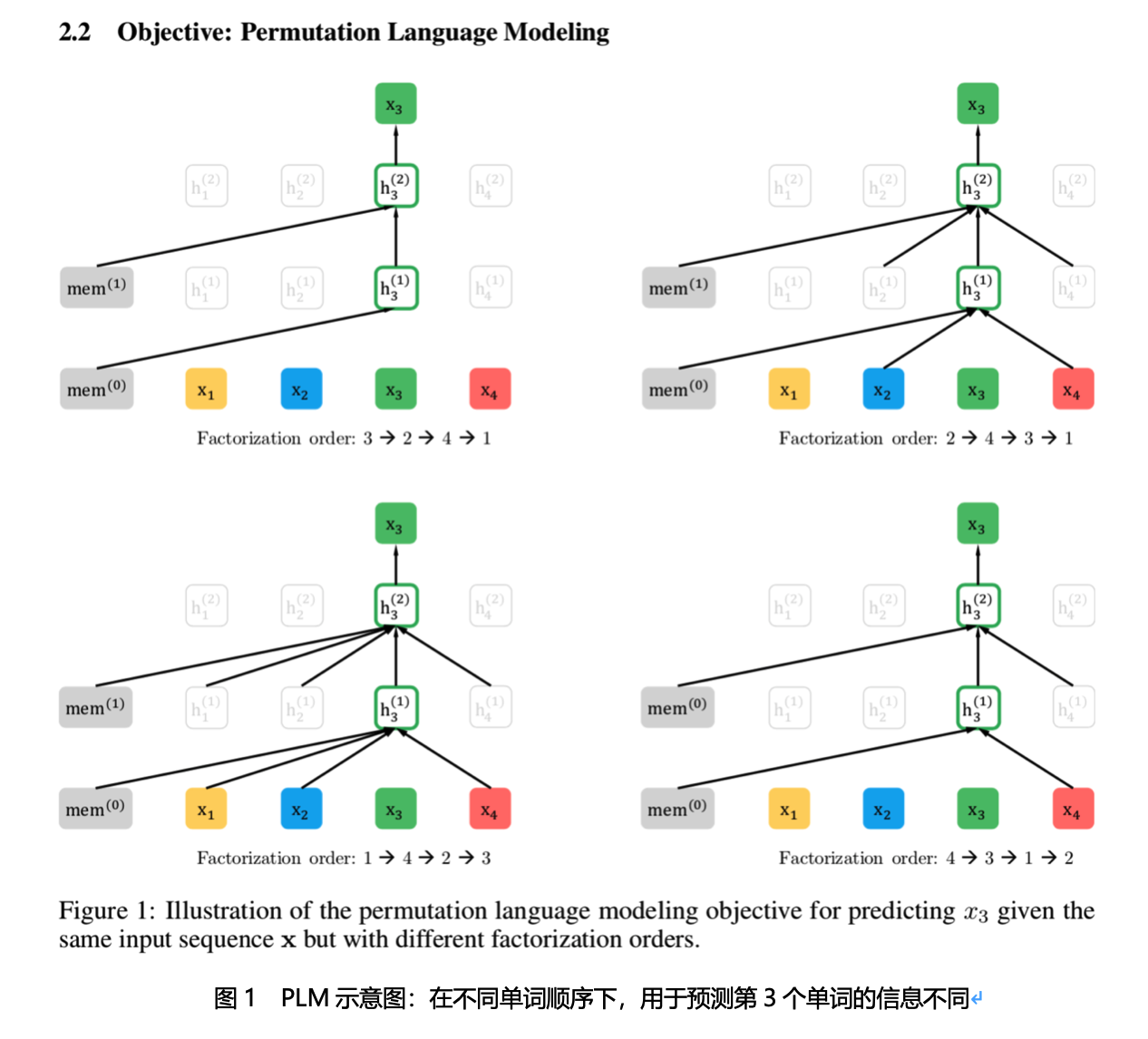
2)Attention掩码的机制
但是直接对单词排列组合会导致句子语义混乱,因此,预训练阶段的输入部分,看上去仍然是原始的语句顺序,但是可以在Transformer部分做些工作。XLNet采取了Attention掩码的机制,实现Permutation Language Model,PLM。
假设当前的输入句子是X,要预测的单词Ti是第i个单词,一般情况下,只有前面1到i-1个单词,用于Ti的预测,但是在Transformer内部,通过Attention掩码,从X的输入单词里面,也就是Ti的上文和下文单词中,随机选择i-1个,用于Ti的预测(想象中放在Ti的上文位置),把其它单词的输入通过Attention掩码隐藏掉,不让它们在预测单词Ti的时候发生作用,就能够达成我们期望的目标。
排序语言模型的目标函数
理想状态下,针对每一种排列方式,计算每一个词出现的联合概率
实际情况下,仅预测每个词的概率(XLNet maximizes the expected log likelihood of a sequence w.r.t. all possible permutations of the factorization order)
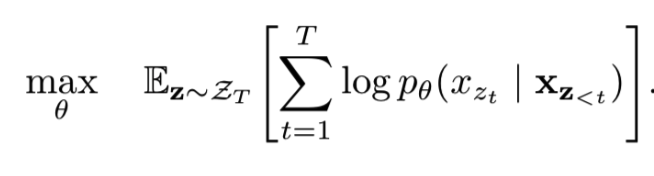
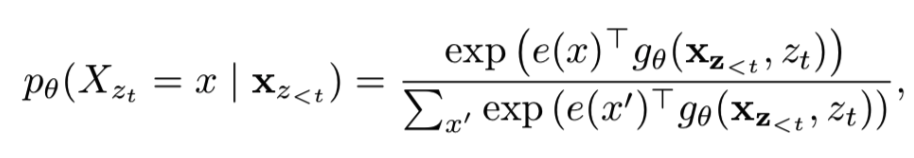
3)双流自注意力模型(masked two-stream attention)
具体的,XLNet采用“双流自注意力模型”实现上述目标。同时预测下一个位置的词(固定位置预测词,即预测下一个位置出现的词,Content流=内容+位置),及预测位置(固定词预测位置,即多种位置扰动后,某个词所在的位置是什么,Query流=位置,相当于BERT的[mask]功能)。主要包括:内容流自注意力(Content stream self-attention)和Query流自注意力(Query stream self-attention)。
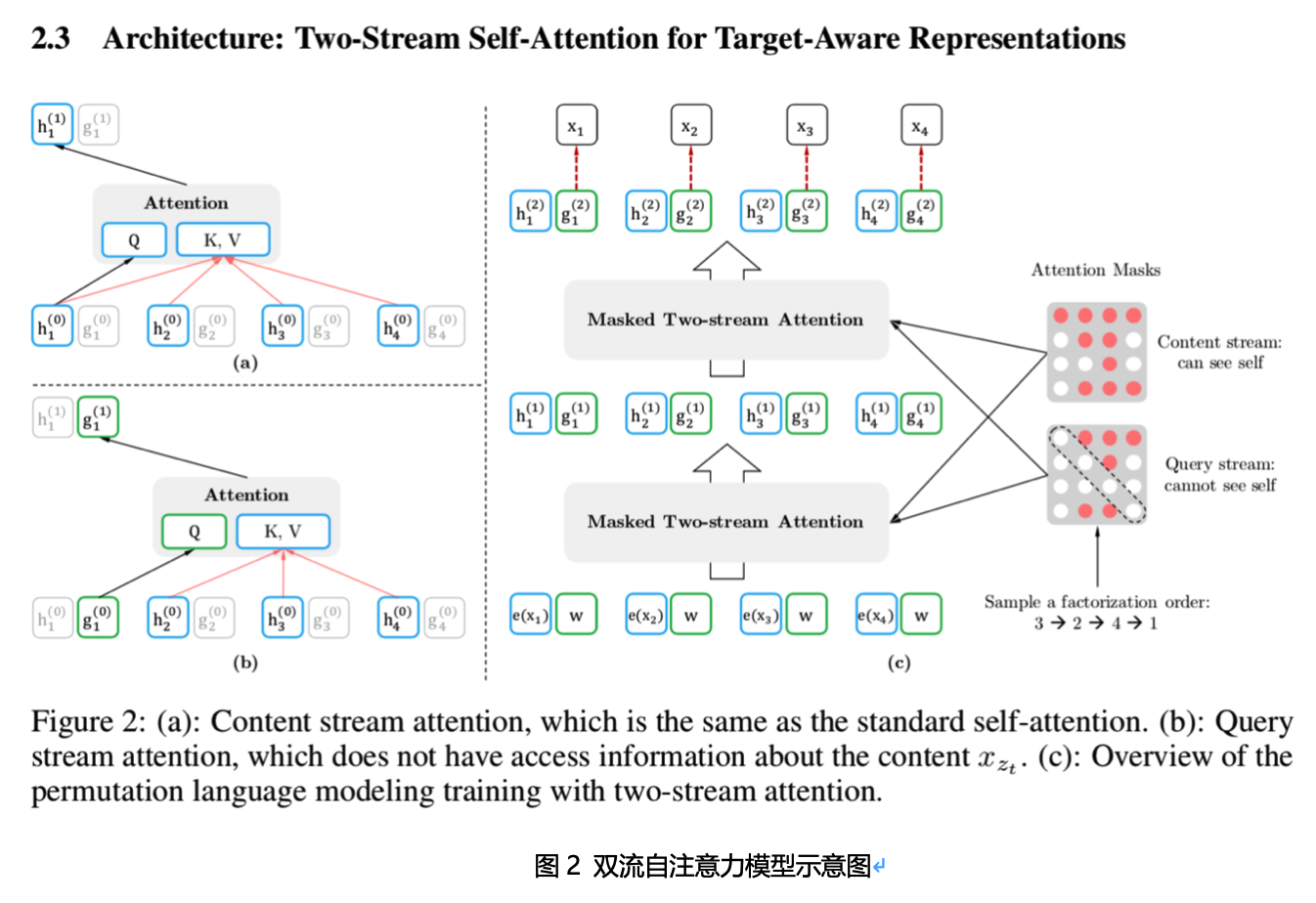
优势
XLNet就是Bert、GPT 2.0和Transformer XL的综合体变身。
首先,它通过PLM预训练目标,吸收了Bert的双向语言模型;
然后,吸收了GPT2.0的核心其实是更多更高质量的预训练数据;
BERT语料库基础上(BooksCorpus + Wiki = ~13G),增加Giga5,ClueWeb以及Common Crawl数据,并去掉其中的一些低质量数据,大小分别是16G,19G和78G。
最后,Transformer XL的主要思想也被吸收进来,因此解决了Transformer对于长文档NLP应用不够友好的问题;
由于能够维持表面从左向右的生成过程,可能有利于生成式任务。
K-BERT
Ref: K-BERT: Enabling Language Representation with Knowledge Graph
不同与百度的ERINE,K-BERT将实体间的关系融入到BERT模型中,融入实体关系后,可以体现出除字面意思外的先验知识。
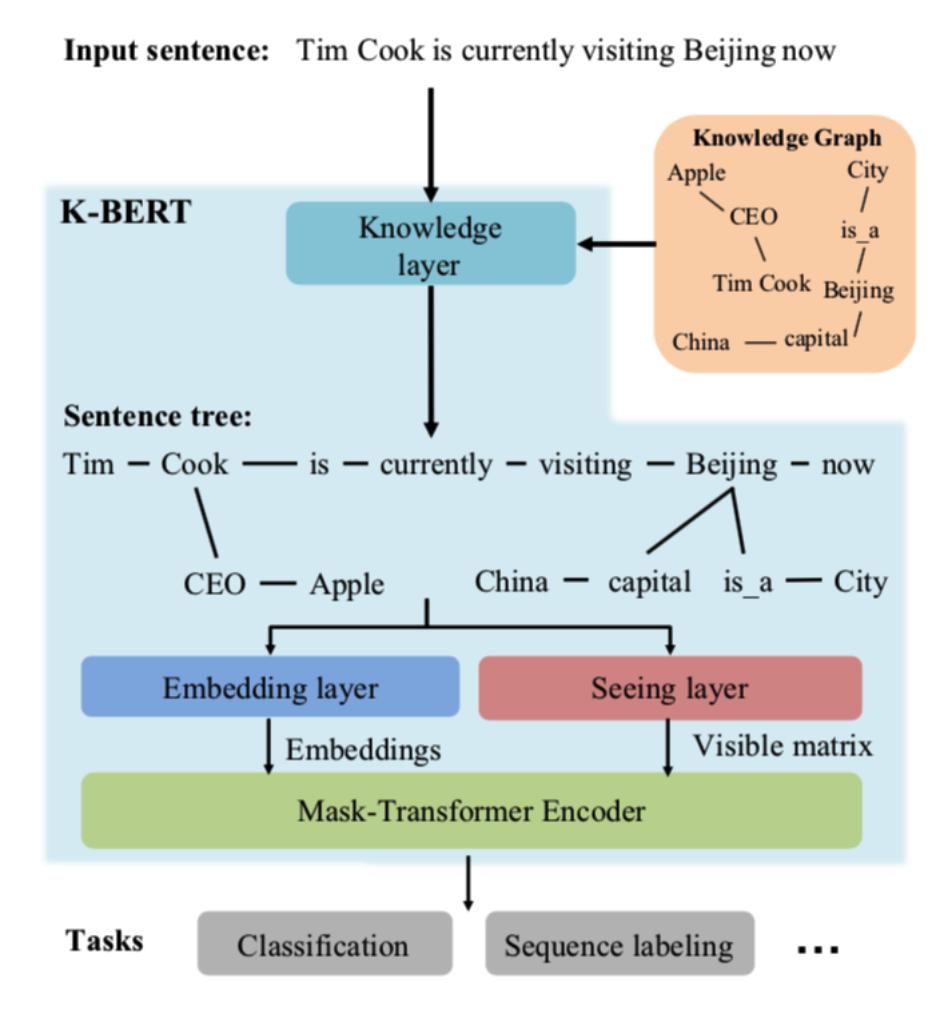
具体如下:
输入语句首先经过知识层(即知识图谱体现的三元组关系),获取到相关的实体
结合相关实体,将输入句子转换成树结构
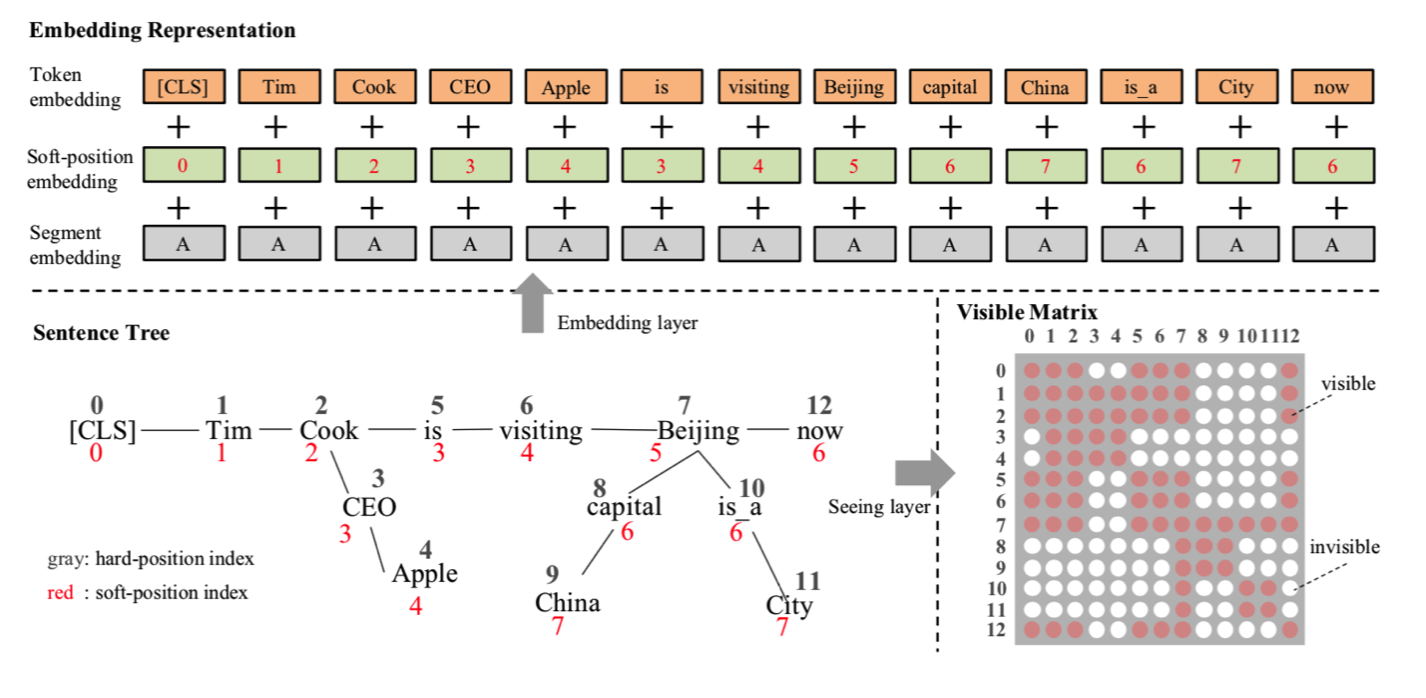
将具有树结构的句子进行软编码(soft-position,红色编码所示)和硬编码(hard-position,黑色所示)
计算可见矩阵(Visible matrix),为0/1值矩阵,决定了self-attention时,哪些词可以跟哪些词是可见的,是可以进行attention的,这里通过图谱连接的实体关系,与原输入文本的其他词是不可见的,即一个词的词嵌入只来源于其同一个枝干的上下文,而不同枝干的词之间相互不影响,例如visiting(6) 与 CLS, Tim(1), Cook(2), is(5), Beijing(7), now(12)均是可见的,与Beijing(7)相关的图谱实体capital(8), China(9), is_a(10), City(11)均是不可见的。
计算mask self-attention,即将可见矩阵加入到Self-attention计算时的softmax中,使得不可见的词之间产生的权重为0,可见词之间的权重计算无影响
针对既定任务,进行与BERT相同的fine-tune训练
优势:K-BERT除了软位置和可见矩阵,其余结构均与 Google BERT 保持一致,这就给 K-BERT 带来了一个很好的特性——兼容 BERT 类的模型参数。K-BERT 可以直接加载 Google BERT、Baidu ERNIE、Facebook RoBERTa 等市面上公开的已预训练好的 BERT 类模型,无需自行再次预训练,给使用者节约了很大一笔计算资源。
MASS
Ref: MASS: Masked Sequence to Sequence Pre-training for Language Generation
MASS 分别用 BERT 类似的 Transformer 模型来做 encoder 和 decoder,它的主要贡献就是提供了一种 Seq2Seq 思想的预训练方案。
UNILM
Ref: Unified Language Model Pre-training for Natural Language Understanding and Generation
可用于生成式任务,UNILM提供了一种优雅的方式,能够让我们直接用单个 BERT 模型就可以做 Seq2Seq 任务,而不用区分 encoder 和 decoder,而实现这一点几乎不费吹灰之力——只需要一个特别的 Mask,简单的来讲,1)通过乱序mask使得attention是双向的(即encoder模式),2)通过顺序mask使得attention是单向的(即decoder模式),3)针对2个句子,对第一个句子使用乱序mask,对第二个句子使用顺序mask,即第一个句子 Attention 是双向的,第二个句子 Attention 是单向(即seq2seq模式)。
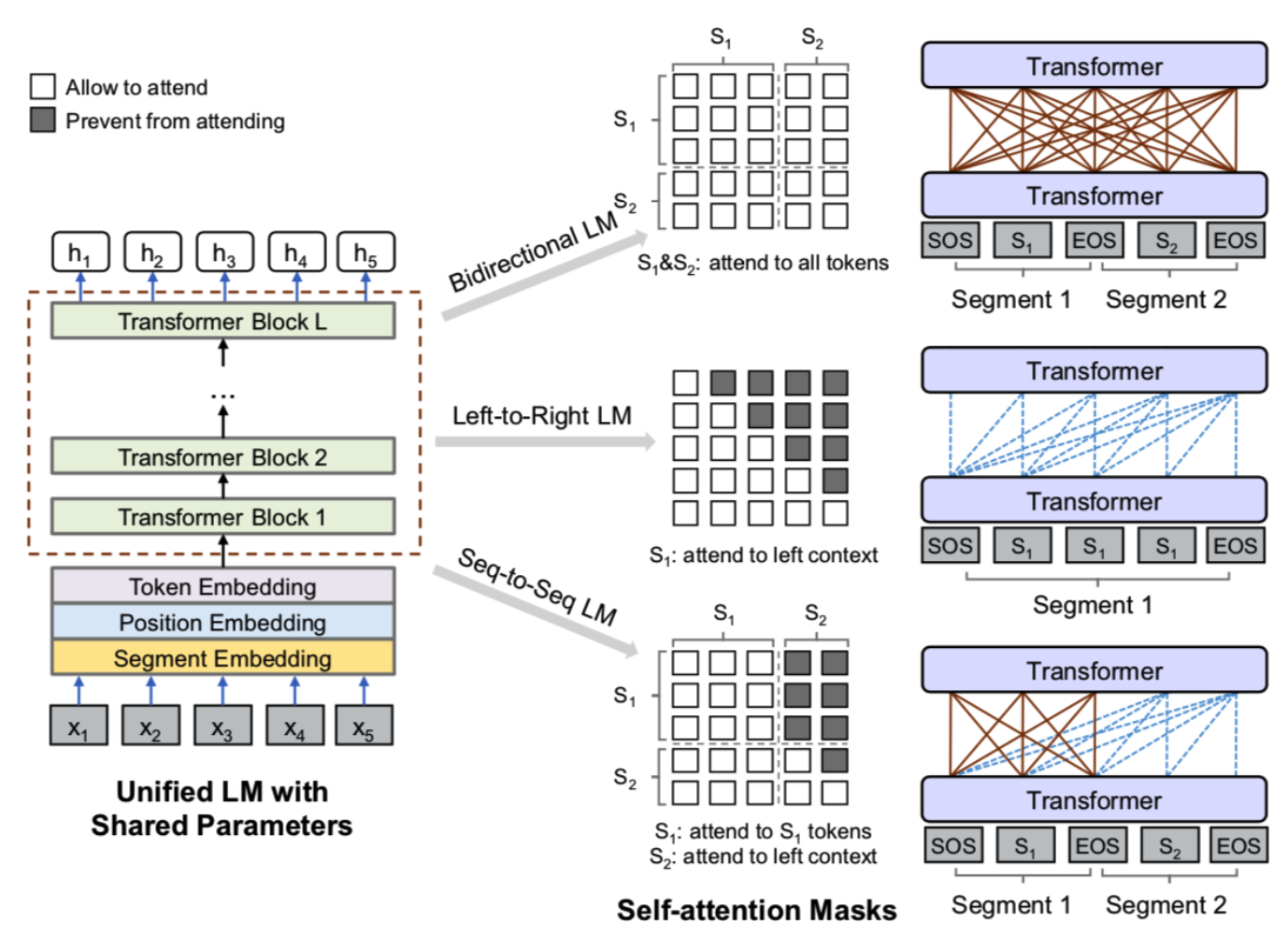
优点:这便是 UNILM 里边提供的用单个 BERT 模型就可以完成 Seq2Seq 任务的思路,只要添加上述形状的 Mask,而不需要修改模型架构,并且还可以直接沿用 BERT 的 Masked Language Model 预训练权重,收敛更快。
参考:
https://mp.weixin.qq.com/s/29y2bg4KE-HNwsimD3aauw
https://arxiv.org/pdf/1906.08237.pdf