最近NLP领域发生了一件大事,一个叫BERT的预训练模型掀起了一场革命式的风波。基于这段时间参读大牛们精细的解析,简单总结下BERT的原理(What)和怎么应用到自己的数据中(How)。
BERT简介
BERT
BERT(Bidirectional Encoder Representation from Transformers),是谷歌AI团队新发布的应用于NLP领域的模型,在11项NLP任务均获得了相当不错的结果,文章于2018年10月发表,并提供了开源地址( https://github.com/google-research/bert ),致谢👏👏👏。
语料库
Corpus: BooksCorpus (800M words) + English Wikipedia (2,500M words).
预训练模型及参数
可参考GitHub详细文档。
BERT的主要特点
Ø 使用Transformer作为特征提取器
Ø 双向语言模型
由于BERT是基于Transformer模型的,而Transformer模型主要基于Attention机制,因此先需要了解下Attention机制。
Attention机制
Attention机制的提出
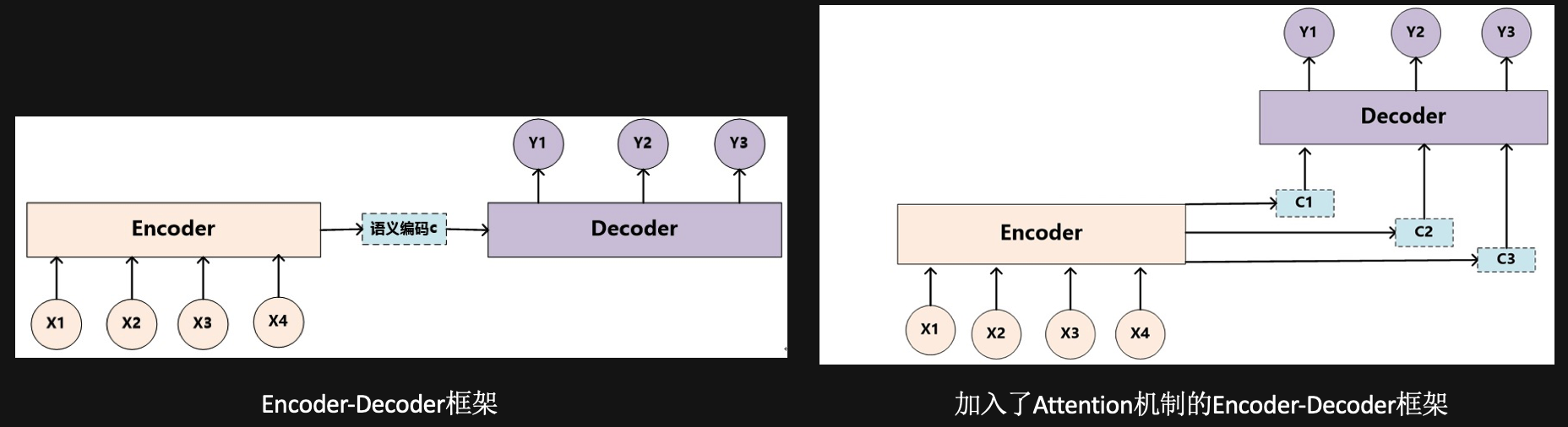
Ø 早在Seq2seq基础上提出attention机制,现在提到的Seq2seq均指加入attention机制的模型
Ø Seq2seq模型:Encoder将整个输入压缩成固定长度的context vector
Ø Attention机制:输入针对不同时刻的输出,有着不同的重要程度(即生成多个context vector)
Ø 重点: 如何计算context vector?
Attention机制的原理
Attention机制主要用于计算输入对不同时刻输出的差异重要程度。
1)对于当前时刻T的输出yt,除了需要计算上一时刻状态St-1之外,还需要知道Encoder对yt的贡献程度Ct;
2)分别计算Encoder不同时刻输入的隐藏层状态hj={h1,h2,…,hT}与Decoder 上一时刻的隐藏层状态St-1的相关性,来获取不同时刻hj的权重,即aij。
3)使用aij与hj对应相乘,再加和,得到整体输入对当前时刻输出的贡献,即Ct。
4)针对不同时刻输出,Ct的内容是不相同的,也即反应了输入对不同时刻输出的差异性。

Attention机制的种类
主要分为以下3种:
1.Context-attention(即Encoder-Decoder Attention)
2.Self-attention(Encoder内部 OR Decoder内部)
3.Multi-head attention(可以是基于Context-attention的,也可以是基于Self-attention的)
基于对Attention机制的理解,我们来看看Transformer模型是什么东东。
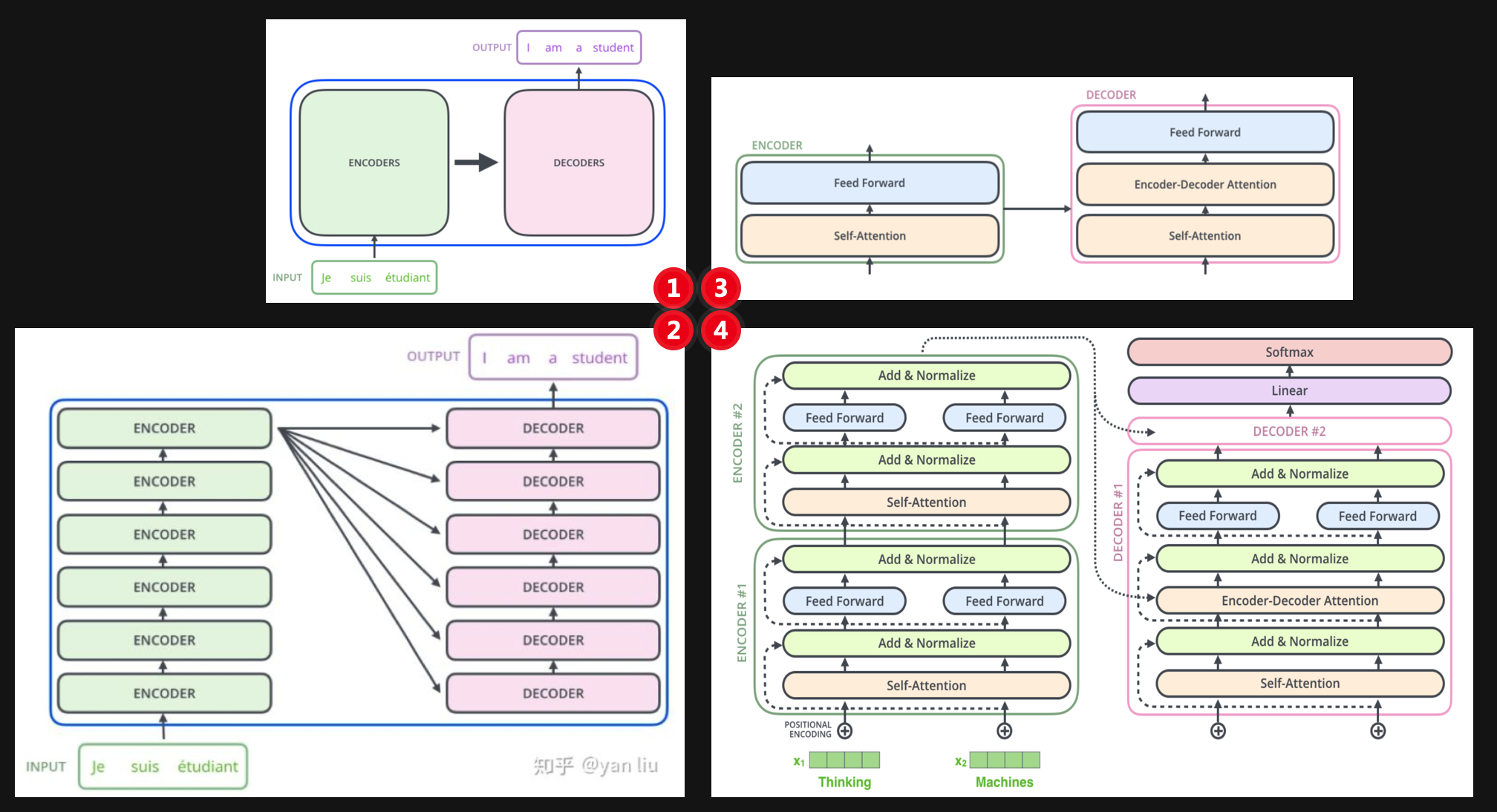
Transformer模型
Transformer模型简介
Transformer 是个叠加的“自注意力机制(Self Attention)”,是目前 NLP 里最强的特征提取器。具体来说,Transformer是一个升级版的seq2seq,也由一个encoder和一个decoder组成的,但是encoder和decoder过程都不用RNN,而且换成了多个attention机制模型。
Ø Encoder:一共有N=6次循环,每次循环包含 2 个layers, 分别是:
One multi-head self-attention mechanism(为输入句子向量的每个词学习一个权重)
One position-wise fully connected feed-forward network
Ø Decoder(right):一共有N=6次循环,每次循环包含3个layers,分别是:
One multi-head self-attention mechanism(当前翻译词与已翻译前文的关系)
One multi-head context-attention mechanism(当前翻译词与编码特征向量的关系)
One position-wise fully connected feed-forward network
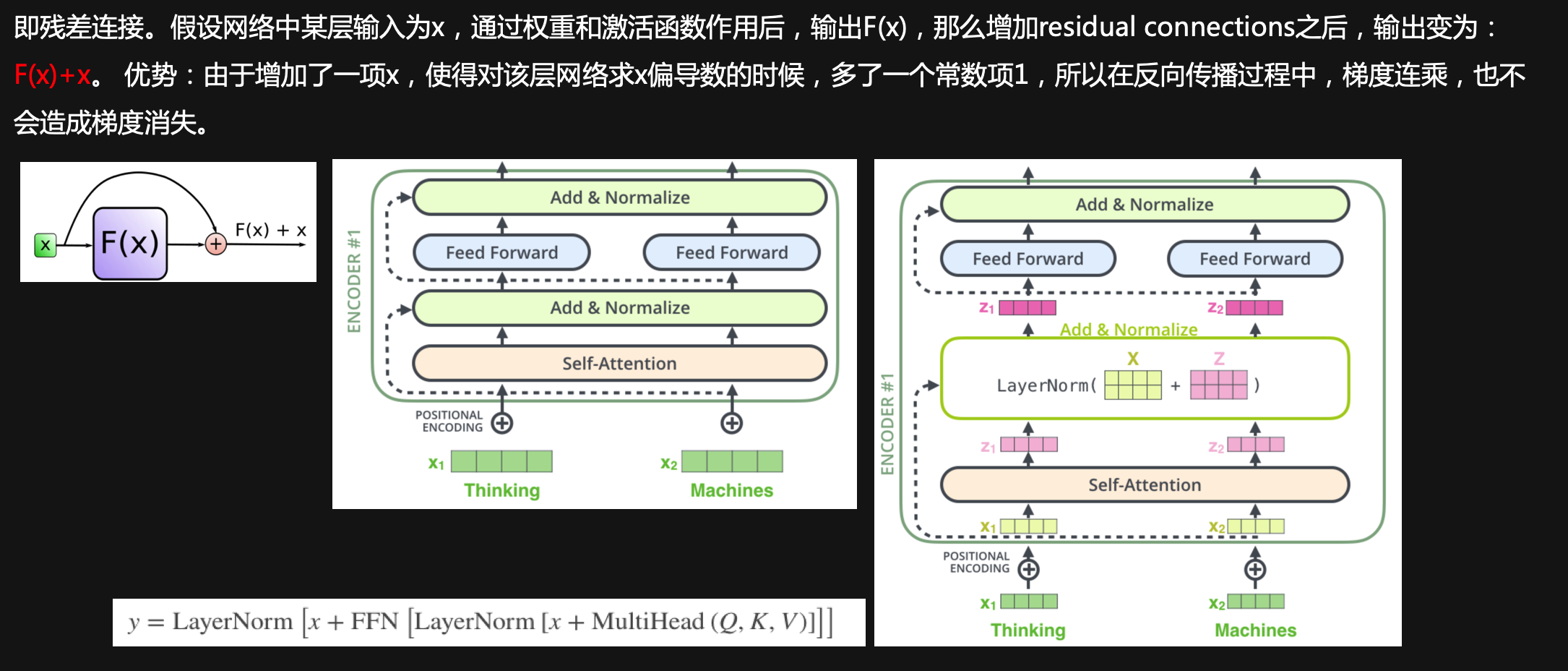
Ø 每个layer后面都跟了一个add&norm,即添加residual connections + layer norm
Transformer模型结构
Encoder部分
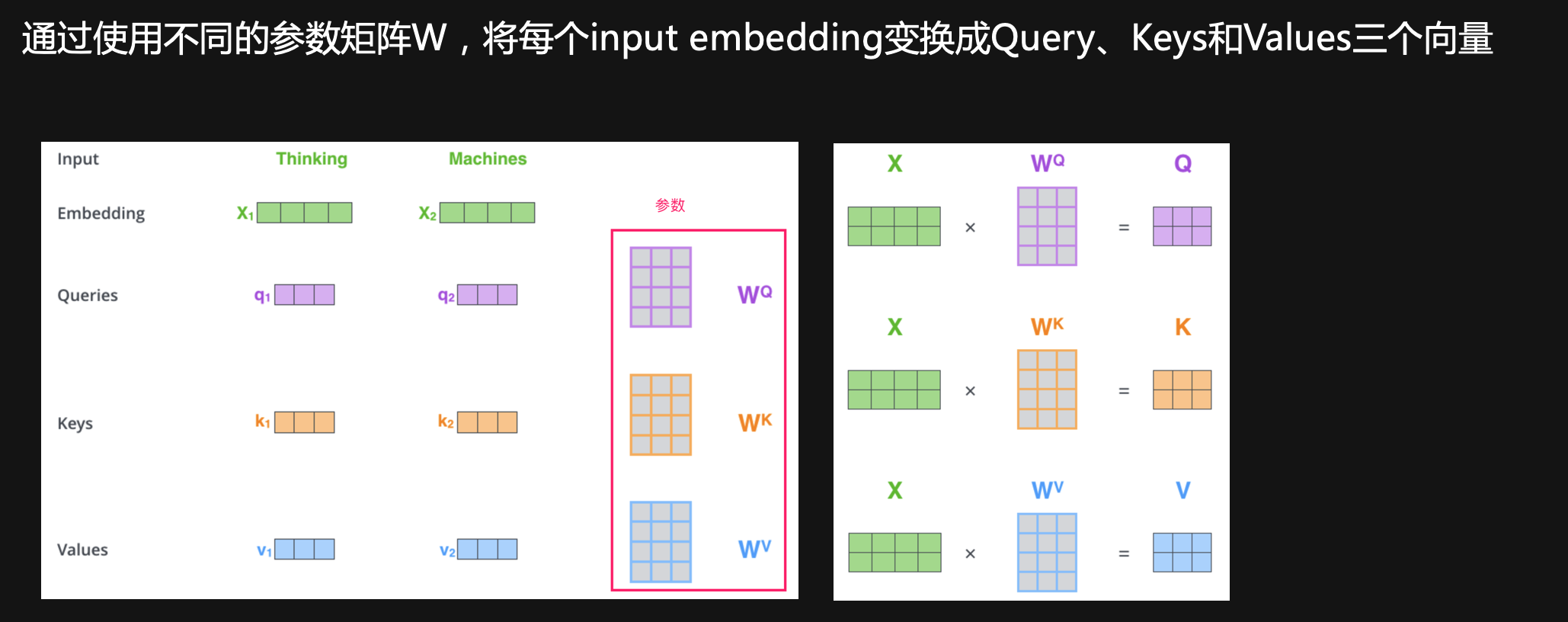
Query+Key+Value
Self-attention
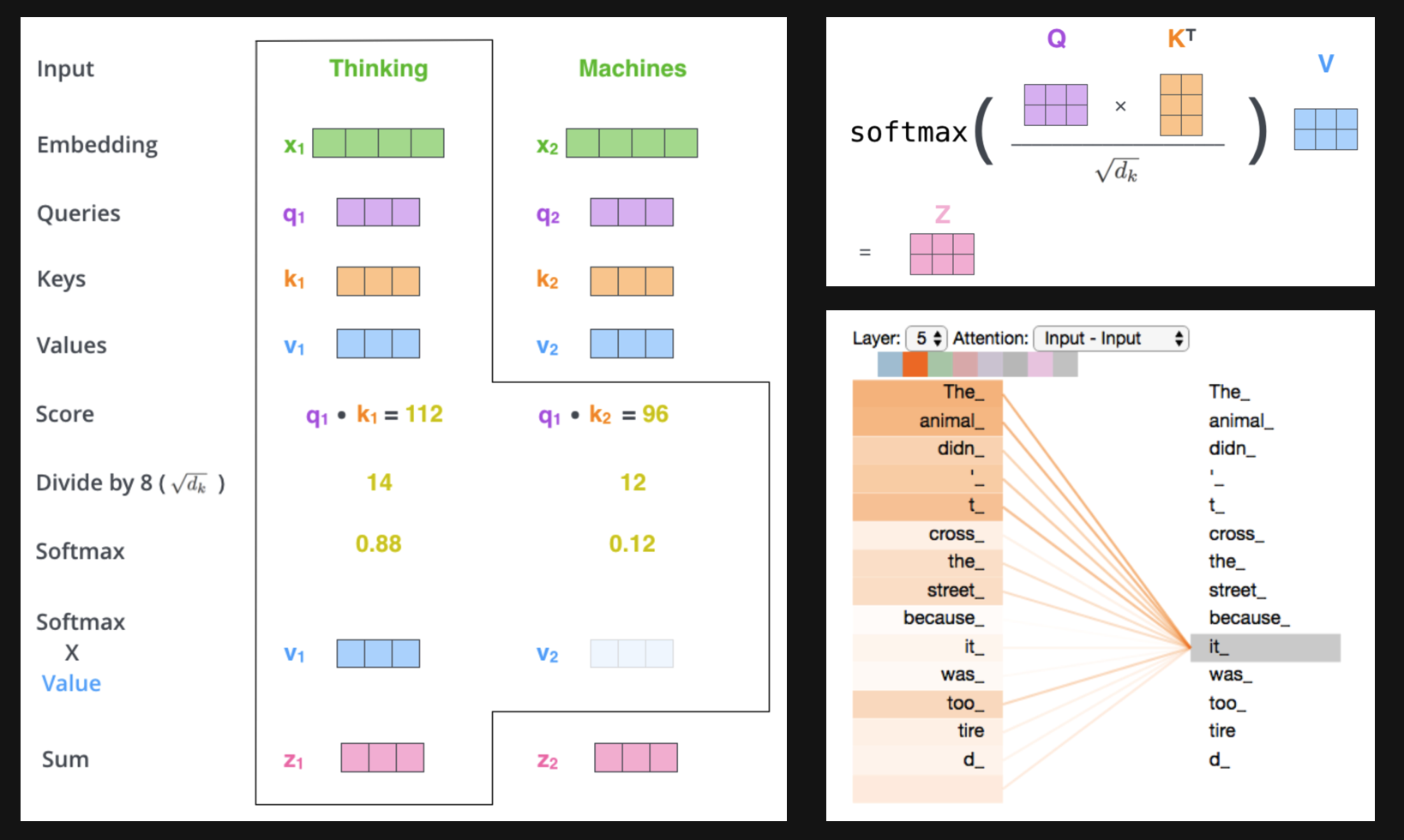
Multi-Head Attention

Heads 数目影响

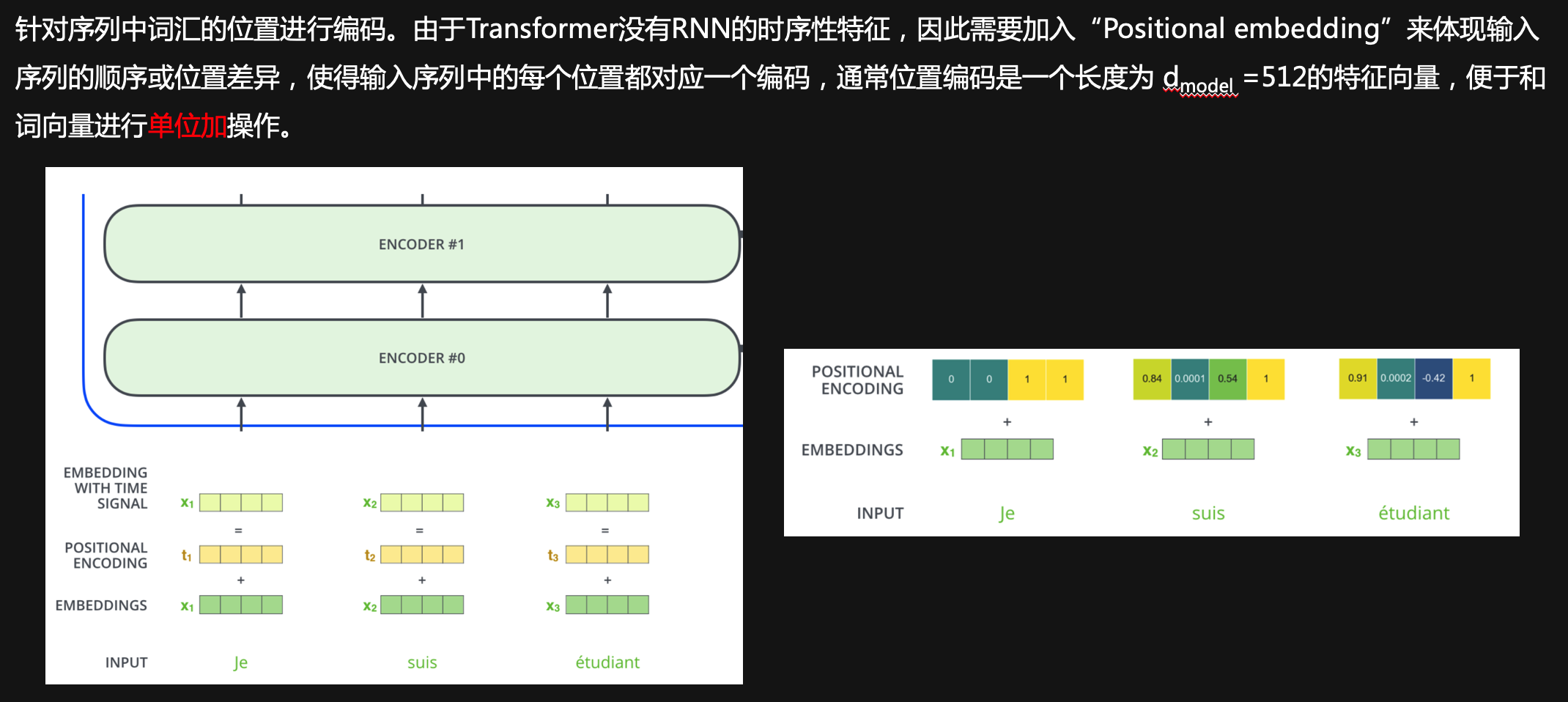
Position embedding
Residual connections and Layer norm
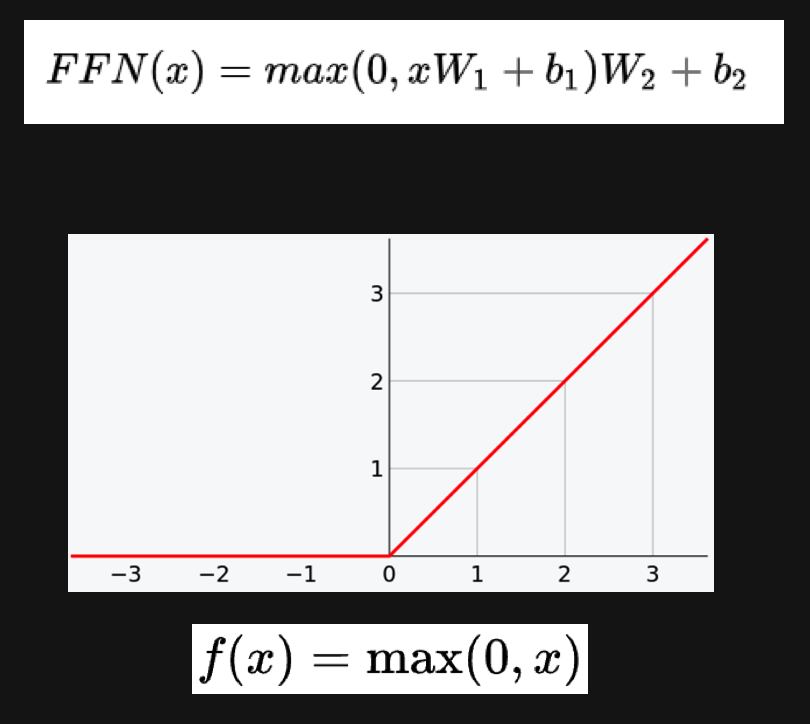
Position-wise feed-forwardnetwork
是一个全连接网络,对每个位置过两个线性层,并使用ReLU作为激活函数。
Decoder部分
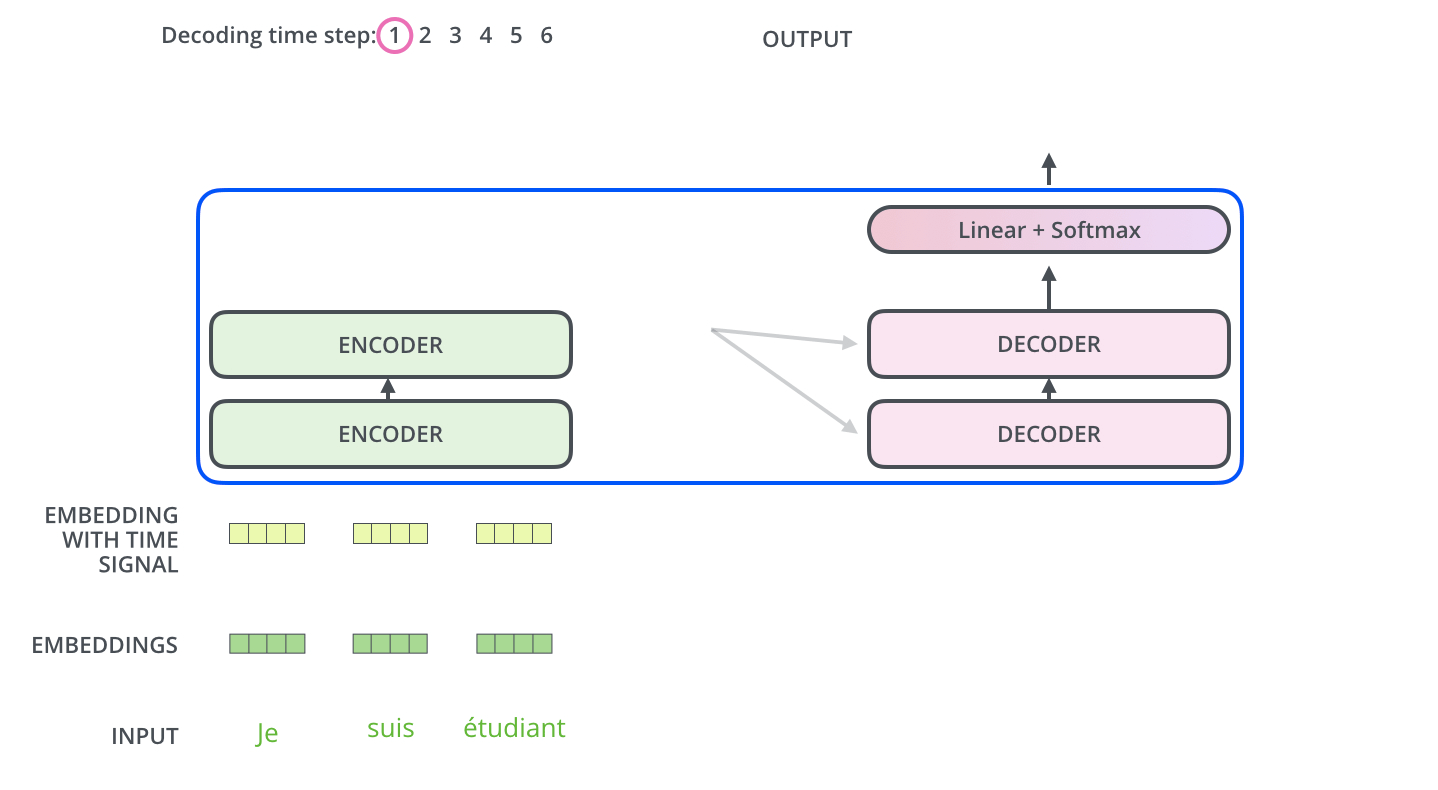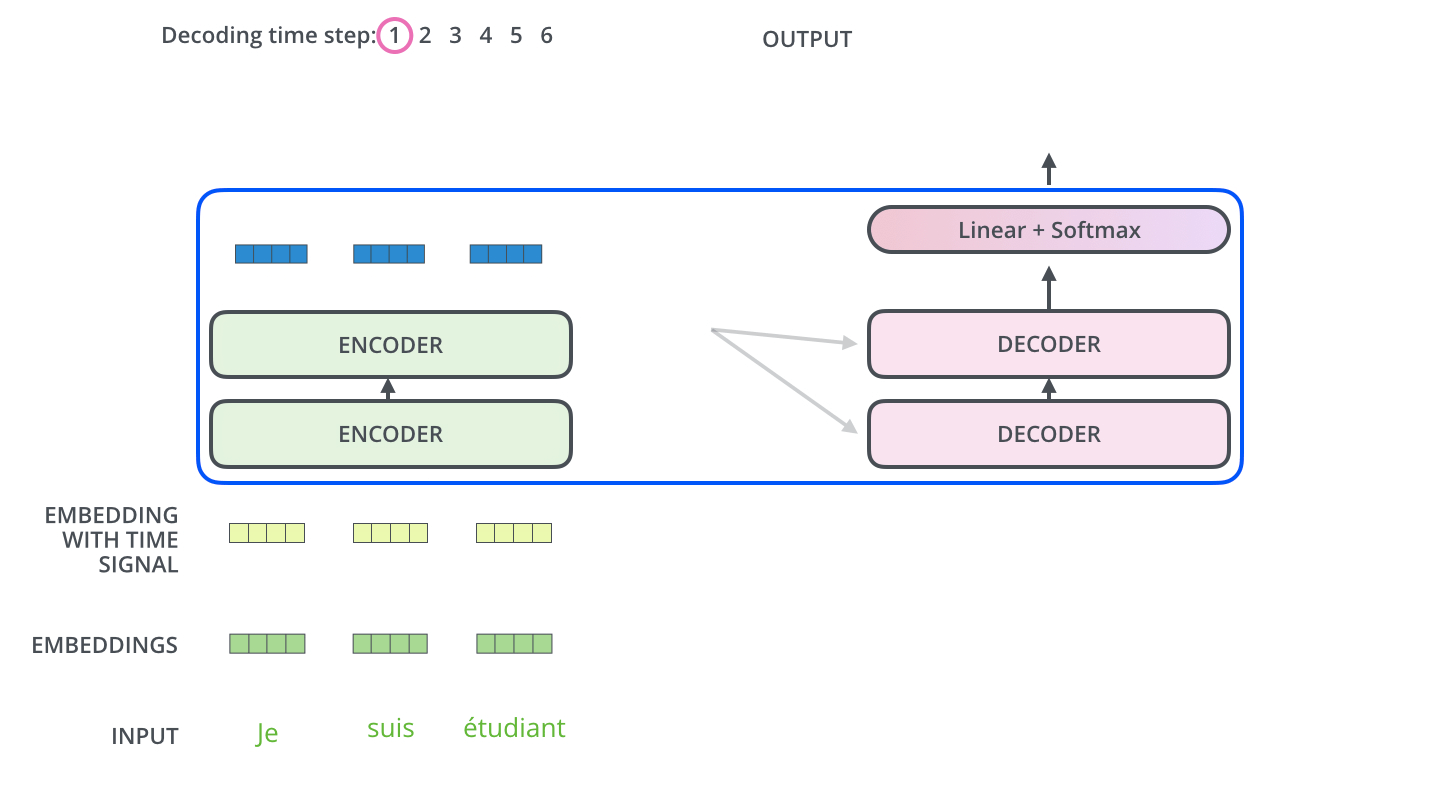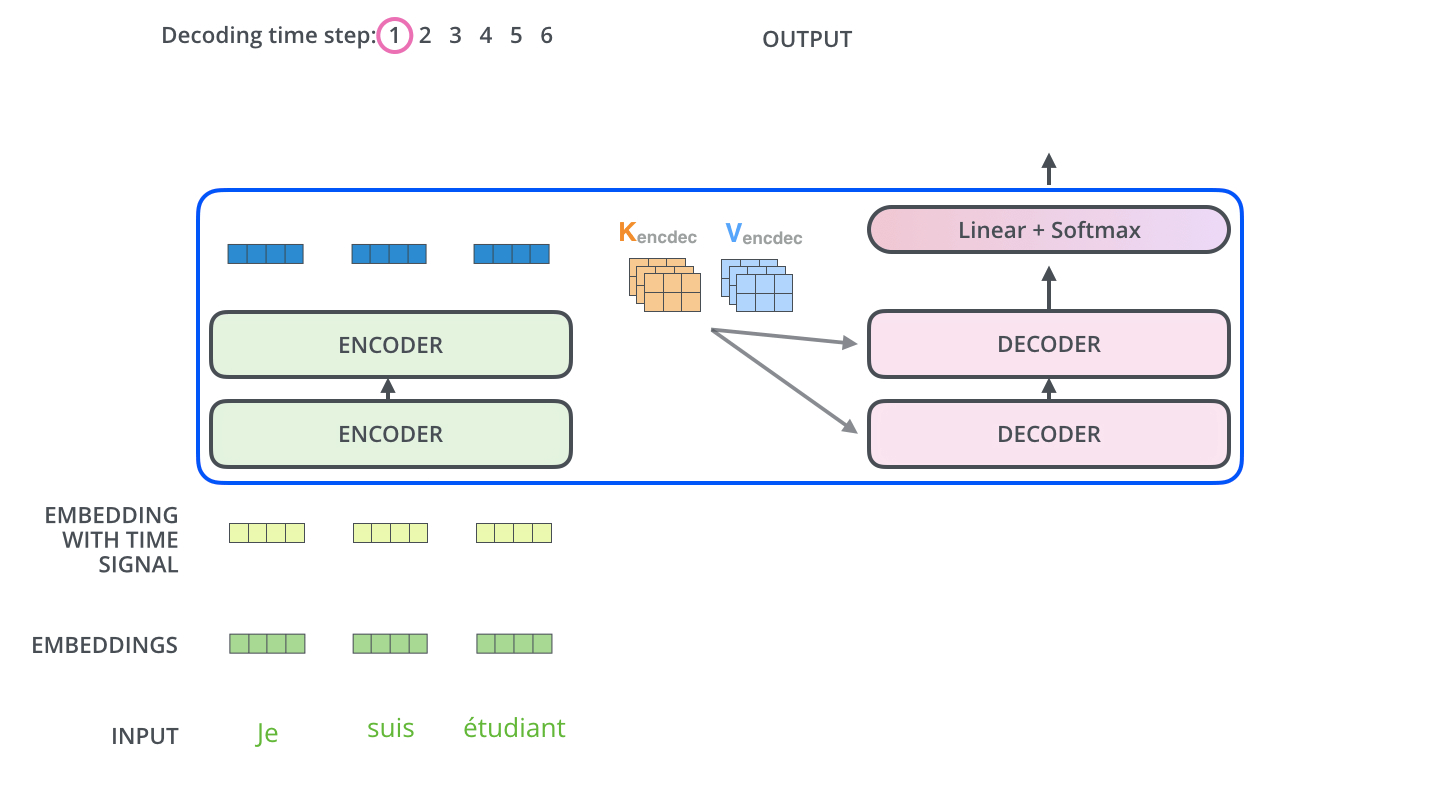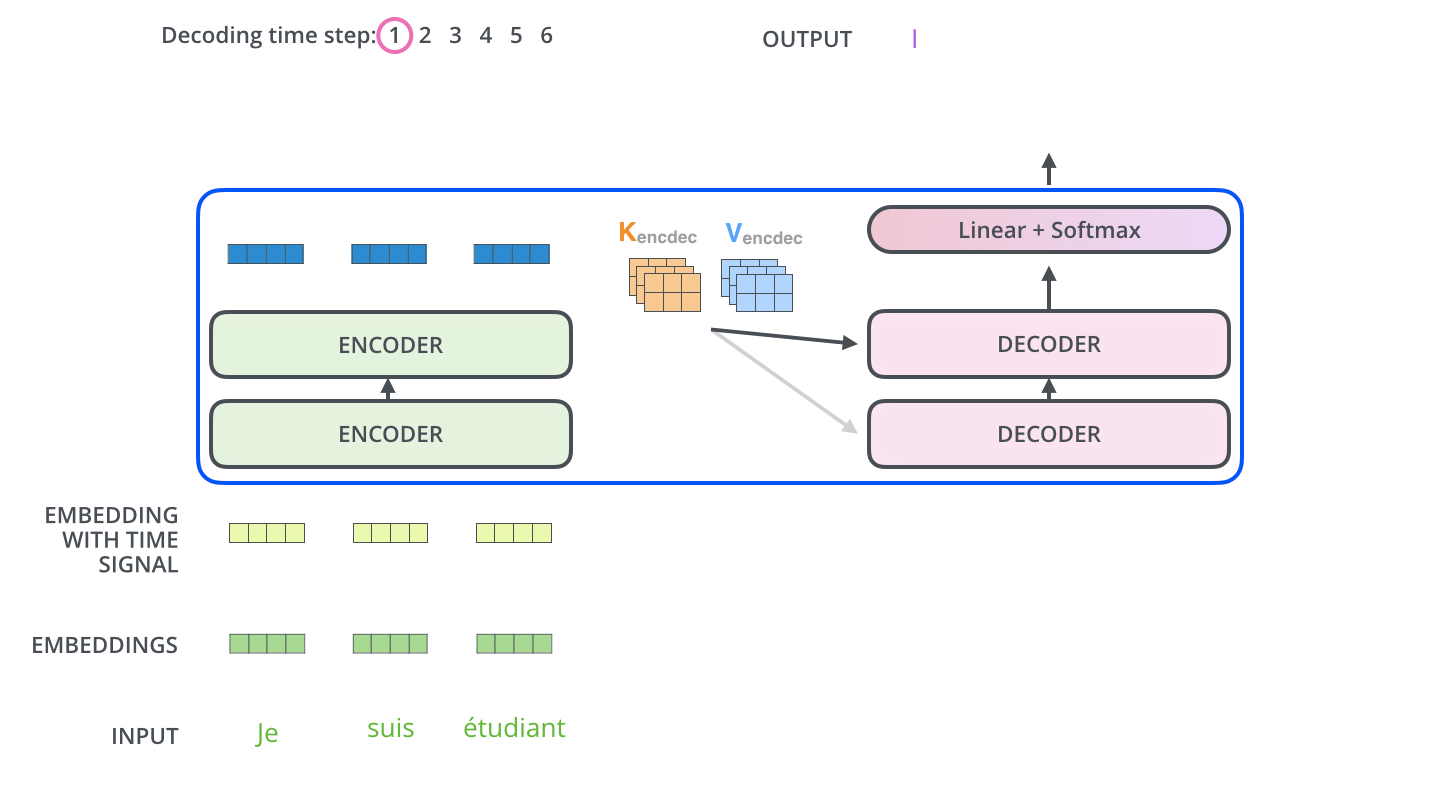
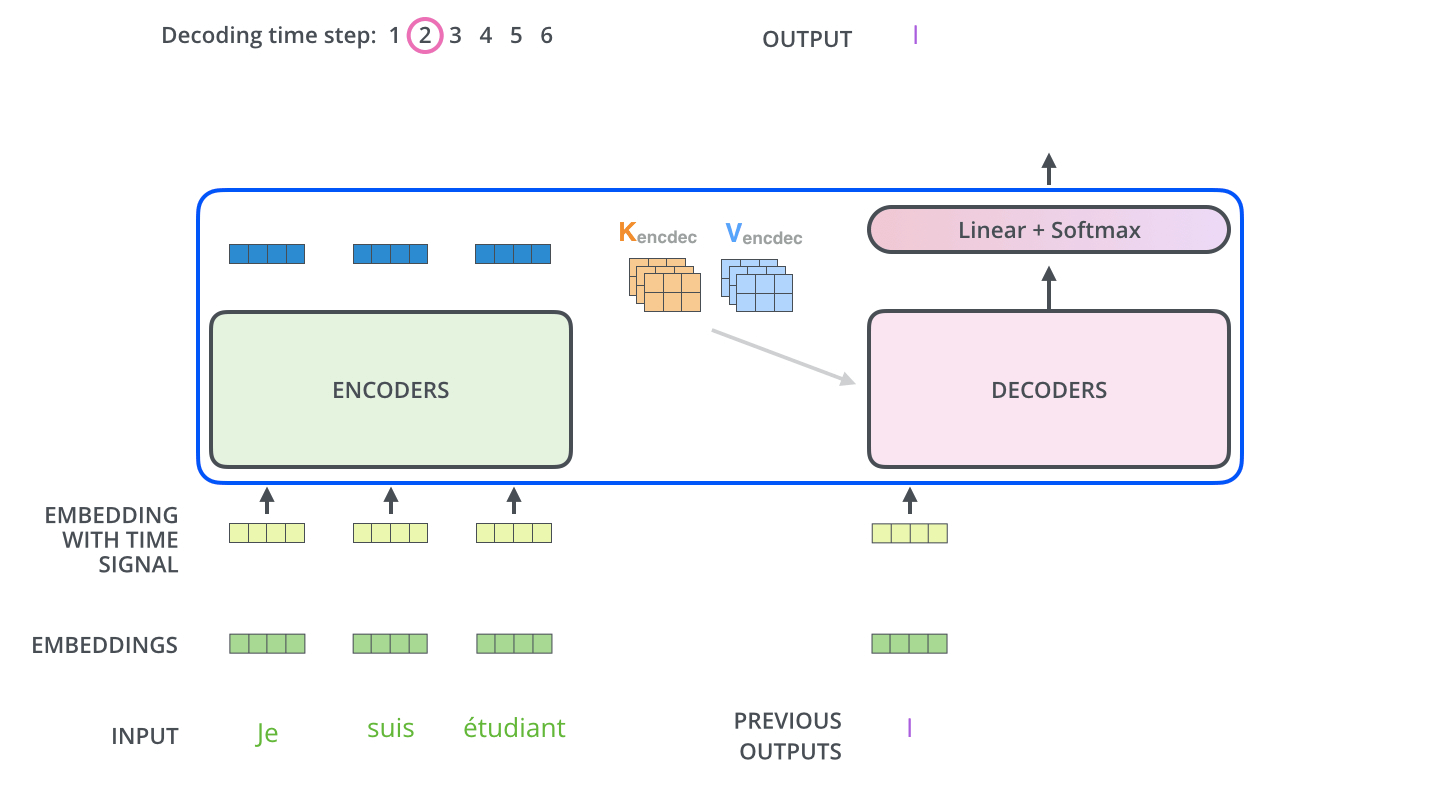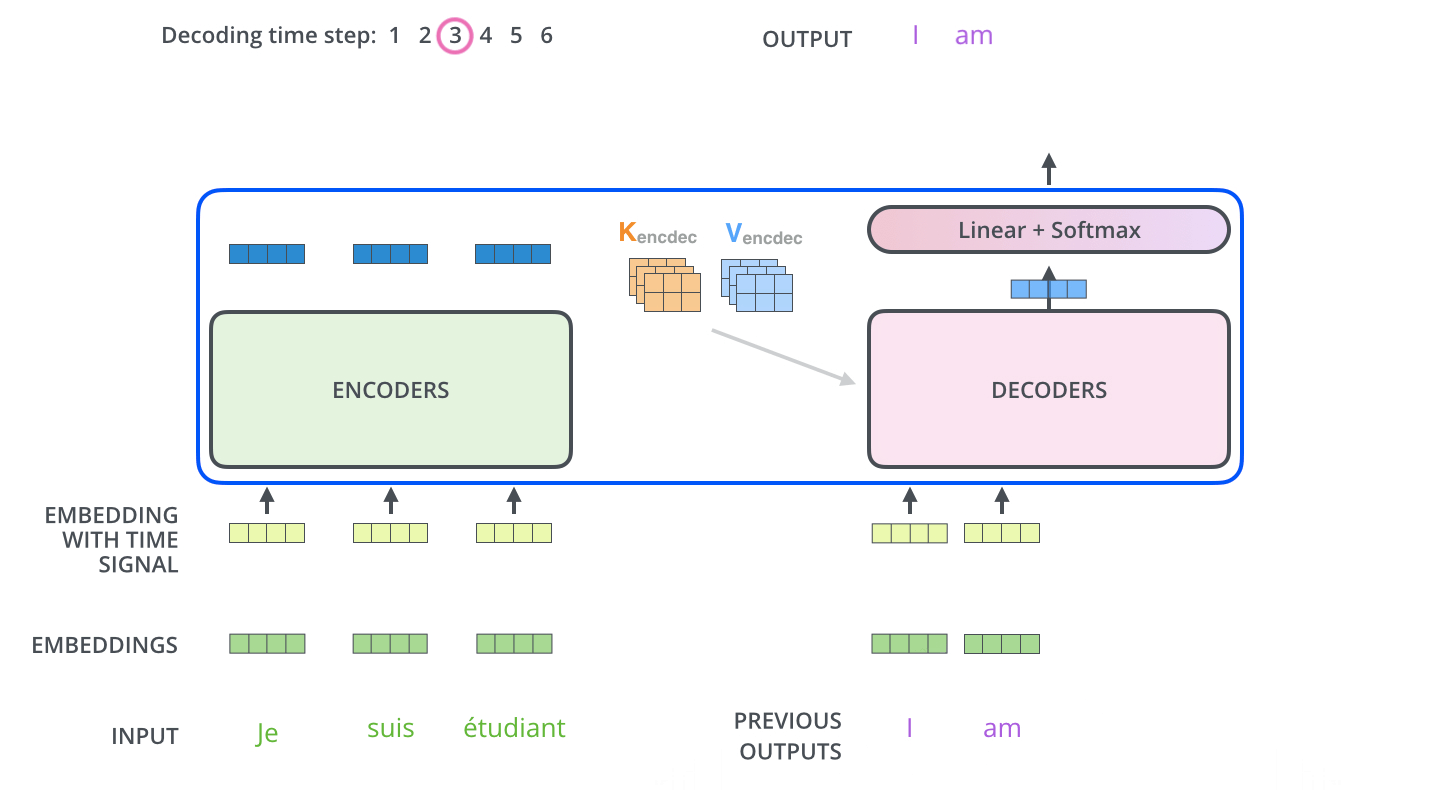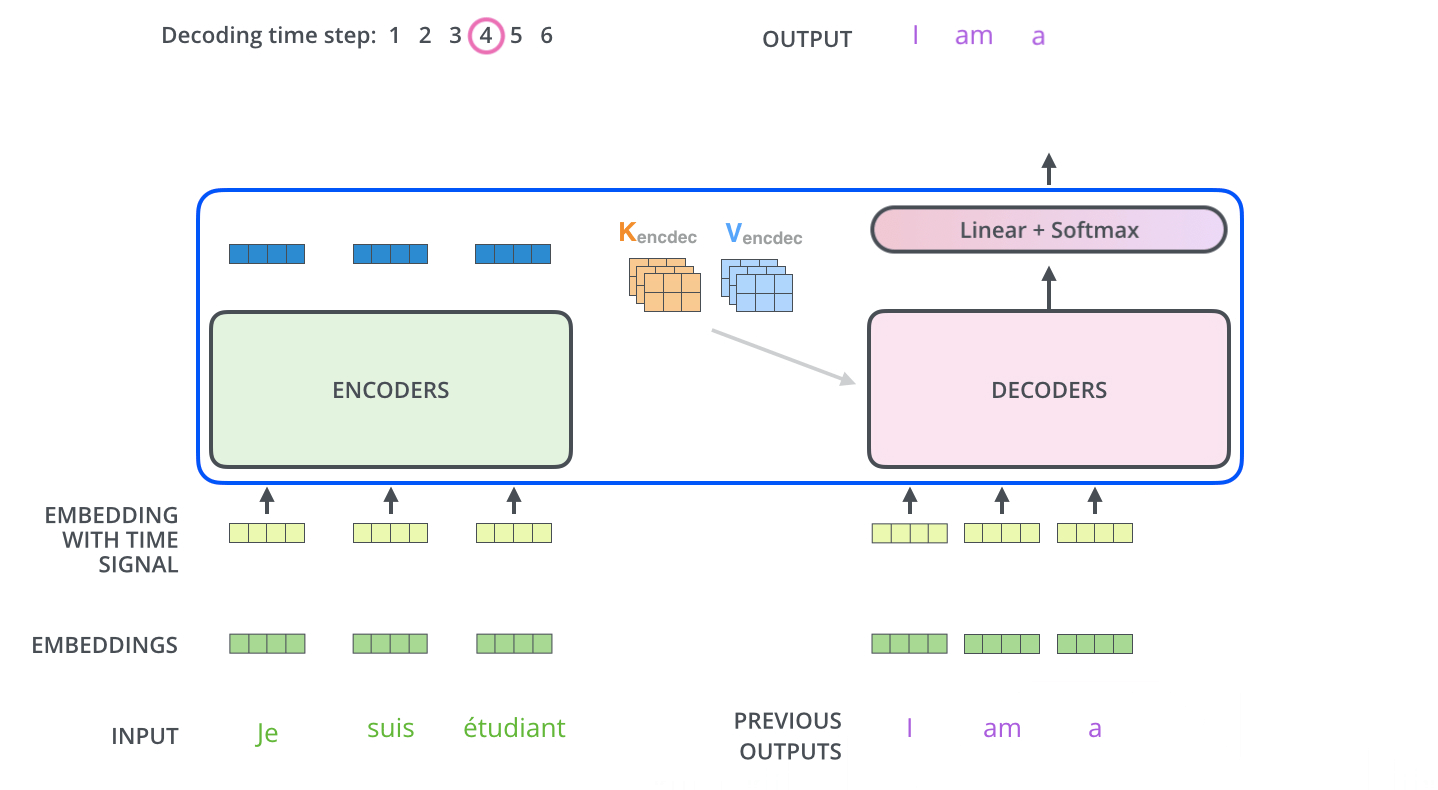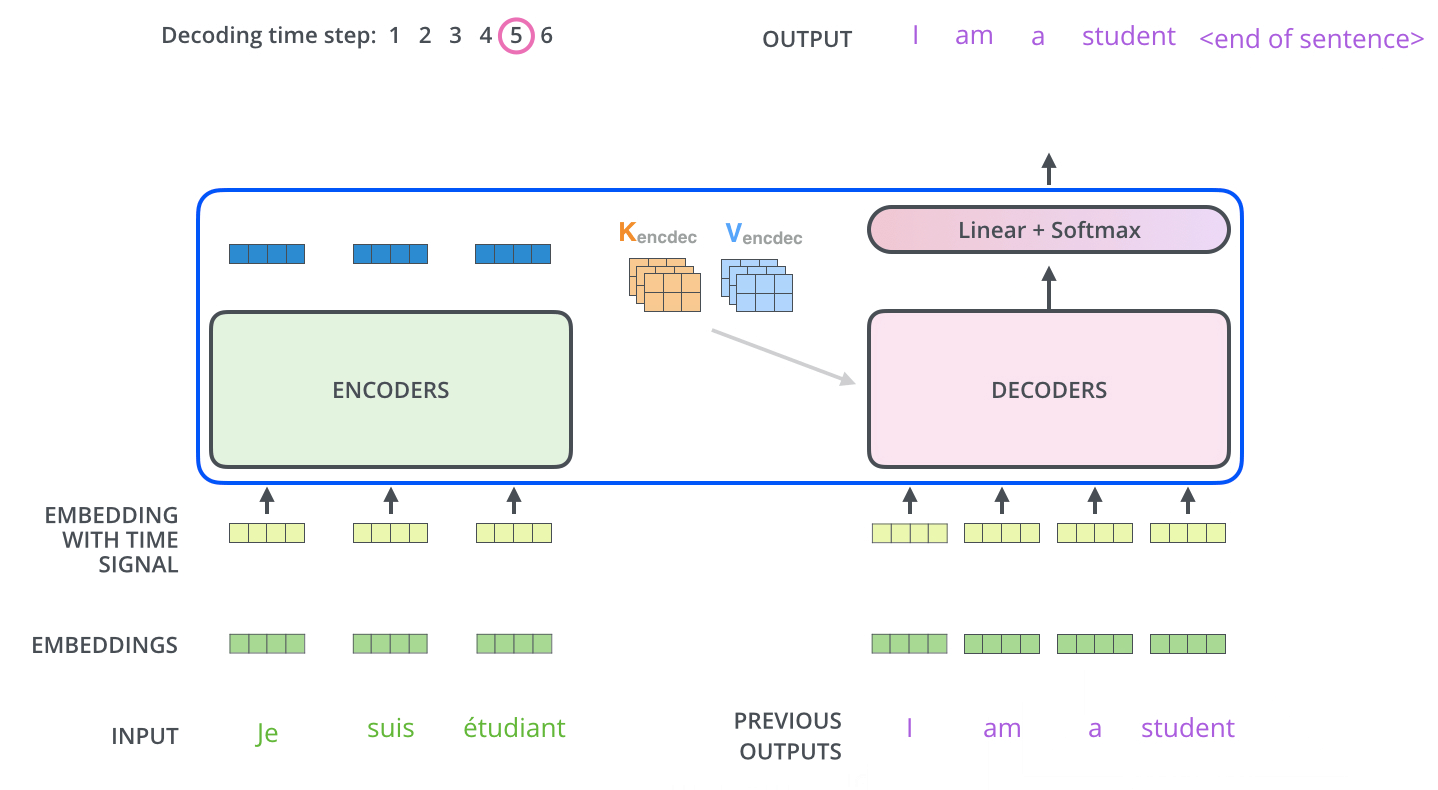
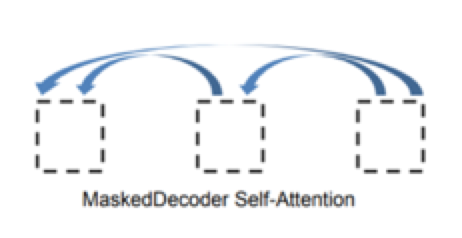
Masked机制
Transformer模型中涉及2种mask:
1.Padding mask用在所有的scaled dot-product attention
由于每次输入的句子长度不一样,需要对输入序列进行对齐,也就是给较短的序列后面填充0。由于填充序列没有什么意义,attention机制不应该把注意力放在这些位置,因此需要进行如下处理:把这些位置的值加上一个非常大的负数(可以是负无穷),这样的话,经过softmax,这些位置的概率就会接近0。
2.Sequence mask用在decoder的self-attention
为了使得Decoder不能看见未来的信息,也就是针对一个序列,在t时刻的解码输出只能依赖于t时刻之前的输出,而不能依赖t时刻之后的输出,因此需要进行一些处理,将t时刻之后的信息隐藏起来。
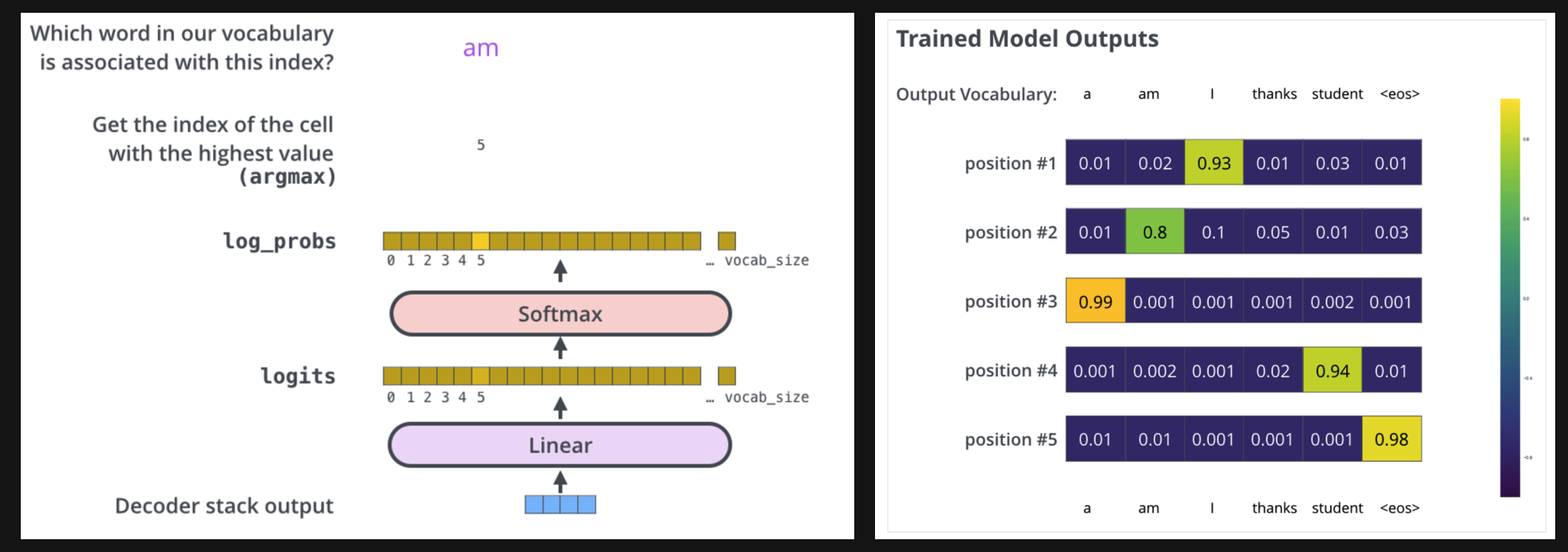
Final Linear and Softmax Layer
Decoder当前输出,经线性变换和softmax ,获得预测概率最大的词,作为输出结果。
Transformer的优势
- 并行计算, 提高训练速度
Transformer用attention代替了原本的RNN;而RNN在训练的时候, 当前step的计算要依赖于上一个step的hidden state的,而Transformer不用RNN,所有的计算都可以并行进行,从而提高的训练的速度。
- 捕获长距离特征
原本的RNN里,如果第一帧要和第十帧建立依赖,那么第一帧的数据要依次经过第二三四五...九帧传给第十帧,进而产生二者的计算;而在这个传递的过程中,可能第一帧的数据已经产生了biased,因此这个交互的速度和准确性都没有保障。而在Transformer中,由于有self attention的存在,任意两帧之间都有直接的交互,从而建立了直接的依赖,无论二者距离多远。
BERT的双向Encoder表示
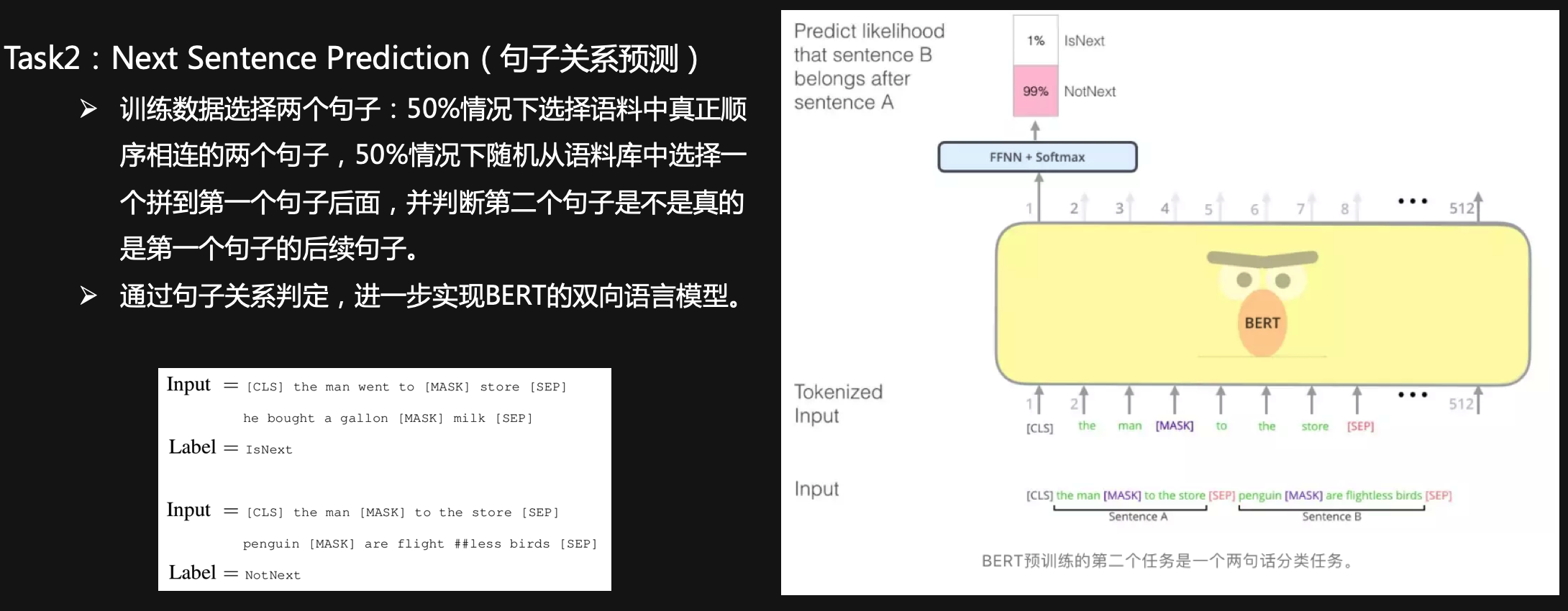
BERT是multi-task语言模型,它的双向语言表示主要是基于以下2个task完成的。
Task1:Masked语言模型(masked LM,即完形填空式预测)

Task2:Next Sentence Prediction(句子关系预测)
Multi-task Learning的损失函数

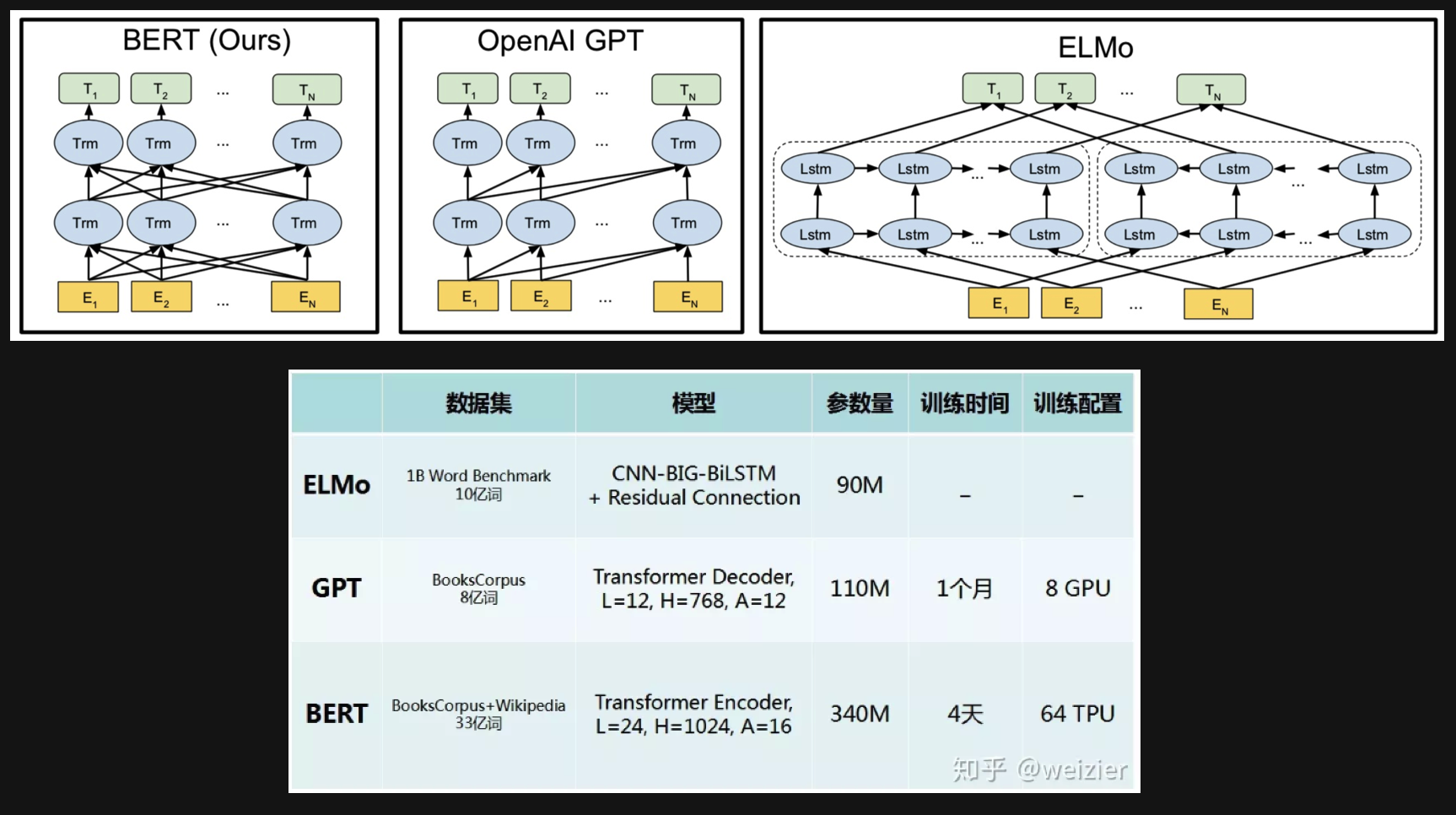
BERT vs. GPT vs. ELMo
BERT与GPT和ELMo的相同和差异,如下:
BERT的应用
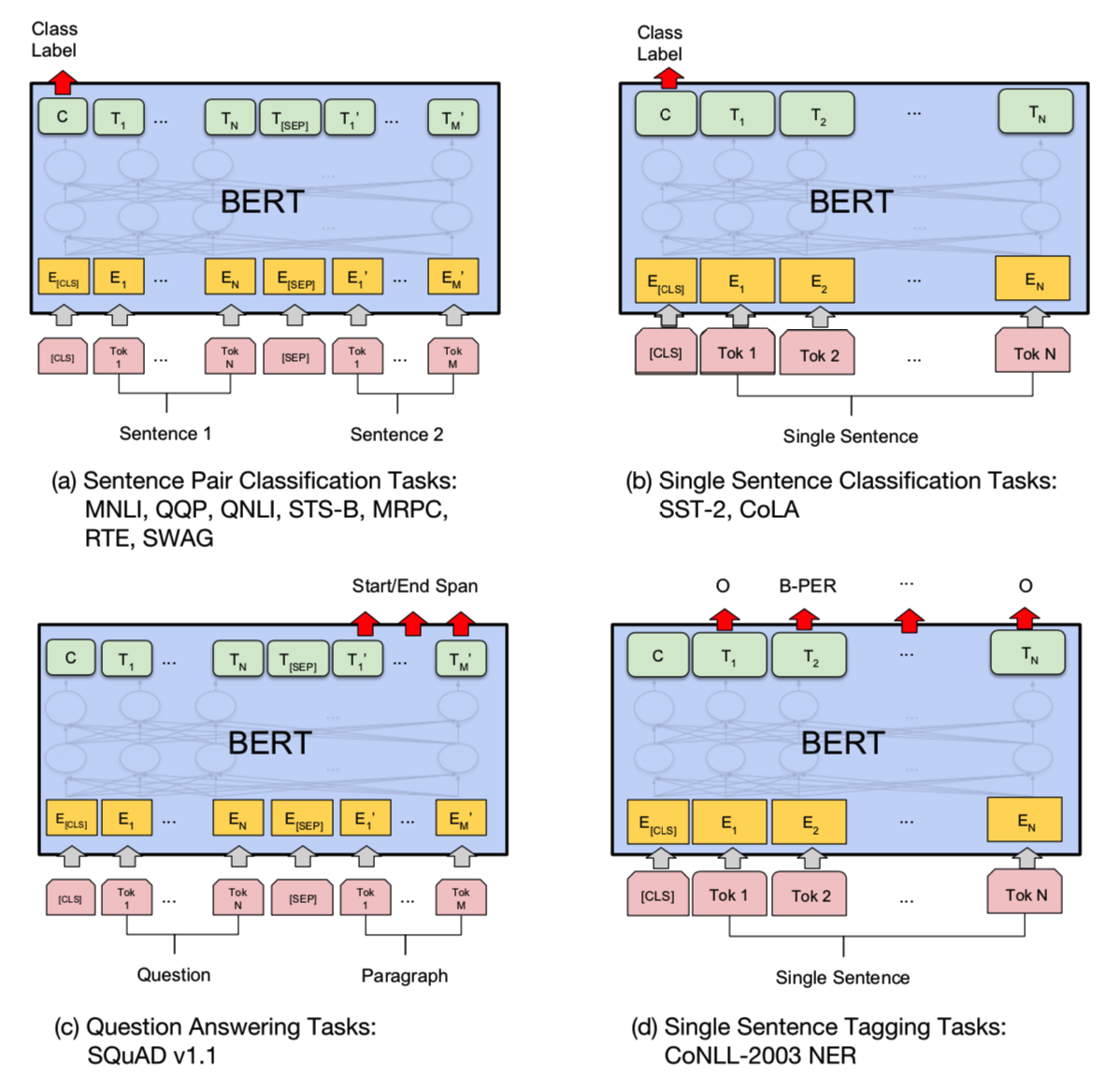
Sequence-level
1)成对句子分类:如MNLI,用于预测第二个句子与第一个句子是承接关系,矛盾关系,还是中立关系?(三分类输出,脚本run_classifier.py)
2)单个句子分类:如CoLA,用于判定给定英语句子的语言可接受性与否?(二分类输出,run_classifier.py)。
Token-level
1)智能问答:如SQuAD v1.1(The Standford Question Answering Dataset),语料为来自Wikipedia的问题和包含答案的段落,用于从段落中预测对应答案的文本跨度(即文本跨度预测问题span prediction task,输出为答案的Start+End+Span,脚本run_classifier.py);
2)命名实体识别:如CoNLL-2003 NER(实体类别Person, Organization, Location, Miscellaneous, or Other (non-named entity)),用于(即token tagging task,输出:,脚本extract_features.py)。
Sentence Encoding/Embedding
使用预训练好的模型,生成句向量(mapping a variable-length sentence to a fixed-length vector)。
https://github.com/hanxiao/bert-as-service
基于pytorch的Bert应用
https://github.com/codertimo/BERT-pytorch
Pre-train, domain-pre-train and fine-tune
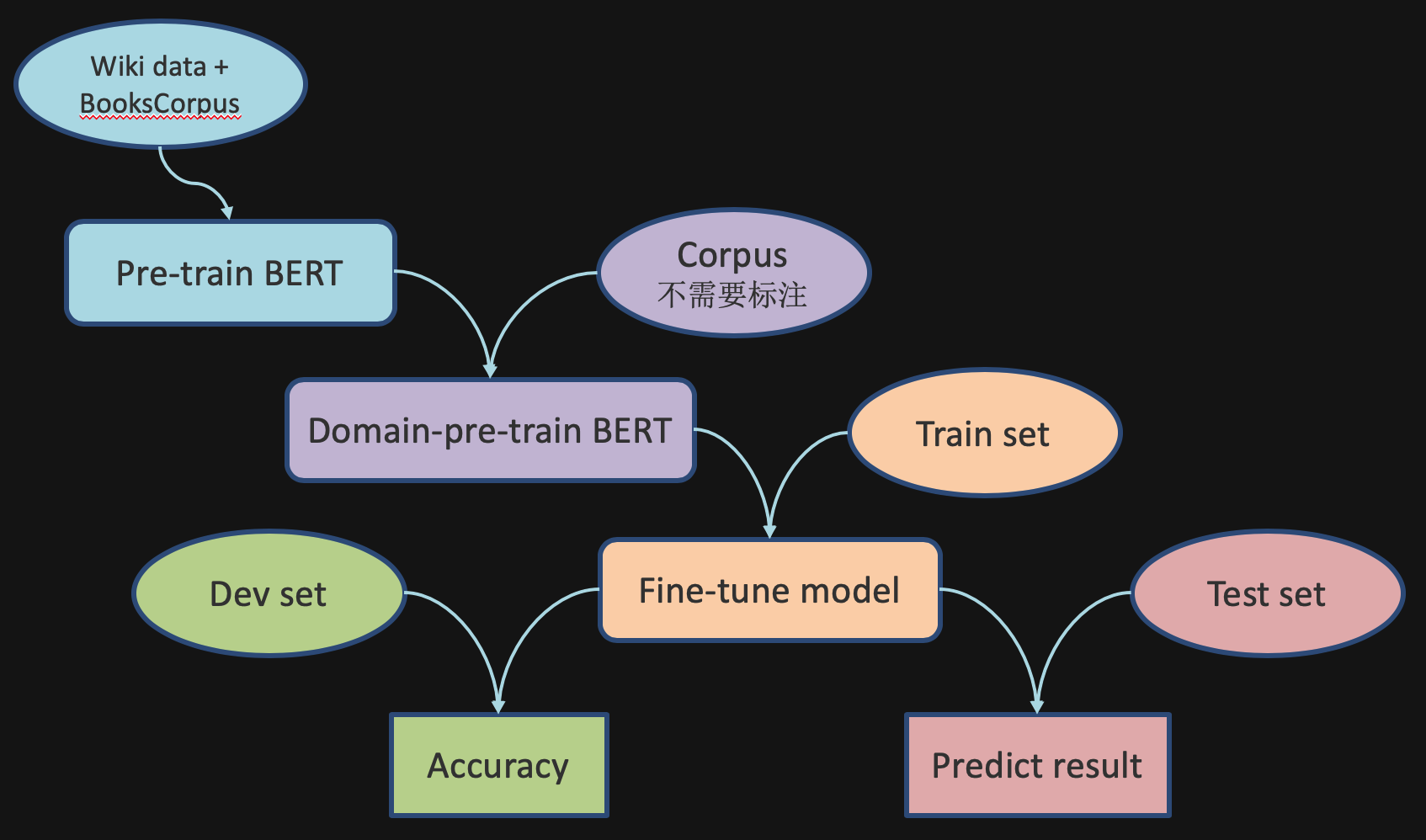
Pre-train参数
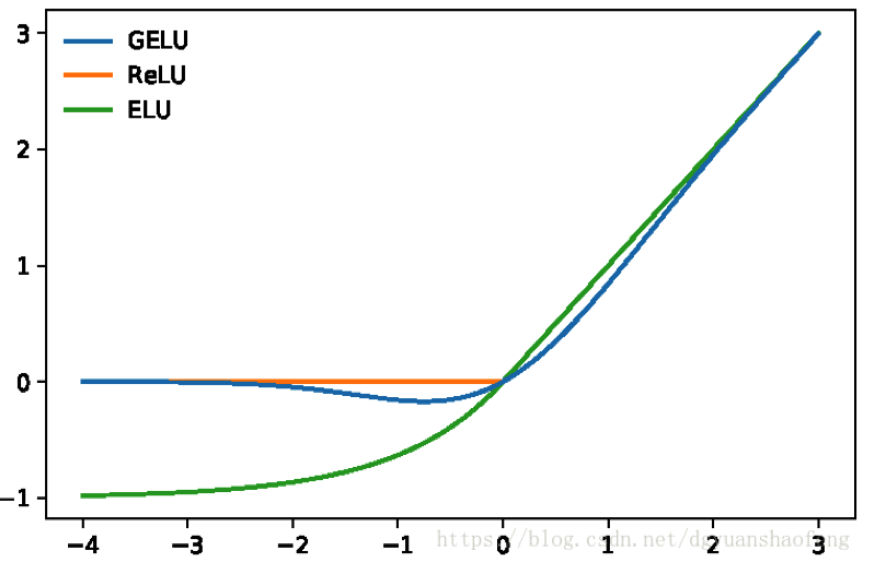
We train with batch size of 256 sequences (256 sequences * 512 tokens = 128,000 tokens/batch) for 1,000,000 steps, which is approximately 40 epochs over the 3.3 billion word corpus. We use Adam with learning rate of 1e-4, β1 = 0.9, β2 = 0.999, L2 weight decay of 0.01, learning rate warmup over the first 10,000 steps, and linear decay of the learning rate. We use a dropout probability of 0.1 on all layers. We use a gelu activation (Hendrycks and Gimpel, 2016) rather than the standard relu, following OpenAI GPT.
Fine-tune参数
For fine-tuning, most model hyperparameters are the same as in pre-training, with the exception of the batch size, learning rate, and number of training epochs. The dropout probability was always kept at 0.1.
!image-20190127000516938](BERT原理和使用/image-20190127000516938.png)

特别鸣谢
https://github.com/google-research/bert
http://nlp.seas.harvard.edu/2018/04/03/attention.html
https://zhuanlan.zhihu.com/p/46833276
https://shimo.im/docs/gmRW4WV2mjoXzKA1/
http://www.52nlp.cn/tag/transformer
https://blog.csdn.net/zuanfengxiao/article/details/78722171
https://yq.aliyun.com/articles/342508
https://www.cnblogs.com/hellcat/p/6925757.html#_label2
https://zhuanlan.zhihu.com/p/38485843
http://jalammar.github.io/illustrated-transformer/
https://zhuanlan.zhihu.com/p/48508221