源码整体框架
地址:https://github.com/google-research/bert
代码结构:
bert
├── CONTRIBUTING.md
├── LICENSE
├── README.md
├── __init__.py
├── create_pretraining_data.py # 自有语料库训练前处理(domain-pre-train)
├── extract_features.py # 实体识别(application)
├── modeling.py # 模型构建
├── modeling_test.py #
├── multilingual.md
├── optimization.py # 参数寻优(梯度下降)
├── optimization_test.py #
├── requirements.txt # 环境
├── run_classifier.py # 文本分类(application)
├── run_pretraining.py # 加入自有语料库的预训练(domain-pre-train)
├── run_squad.py # 智能问答(application)
├── sample_text.txt
├── tokenization.py # 进行WordpieceTokenizer
└── tokenization_test.py #
模型载入参数
config.json文件:
{
“attention_probs_dropout_prob”: 0.1,
# 每个block中attention的dropout(在softmax(query*key)获取value的权重时)
“hidden_act”: “gelu”, # 每个block中feed-forward的激活函数、整体输出层的激活函数
“hidden_dropout_prob”: 0.1, # 每个block中add残差连接后的dropout、整体输出层的dropout
“hidden_size”: 768,
# 每个block中multi-heads attention最后一个连接维度(768 = 12 * 64)(H)
“initializer_range”: 0.02, # tf.truncated_normal_initializer的stdev
“intermediate_size”: 3072, # 每个block中feed-forward隐藏层大小(4H)
“max_position_embeddings”: 512, # position embedding 最大长度
“num_attention_heads”: 12, # 每个block中attention的header数目(A)
“num_hidden_layers”: 12, # Transformer一共有多少个block(L)
“type_vocab_size”: 2, # 输入语句的id大小(如果输入是2个句子,则为2)
“vocab_size”: 21128 # 中文语料库的词数目
}
模型结构
多个线性变换
需要注意,模型存在几处线性变换,以更好的理解参数,如下:
- 每一个multi-heads attention的最后一个连接
- 每一层feed-forward的2个线性层(H to 4H and 4H to H)
- 最后输出的全连接层
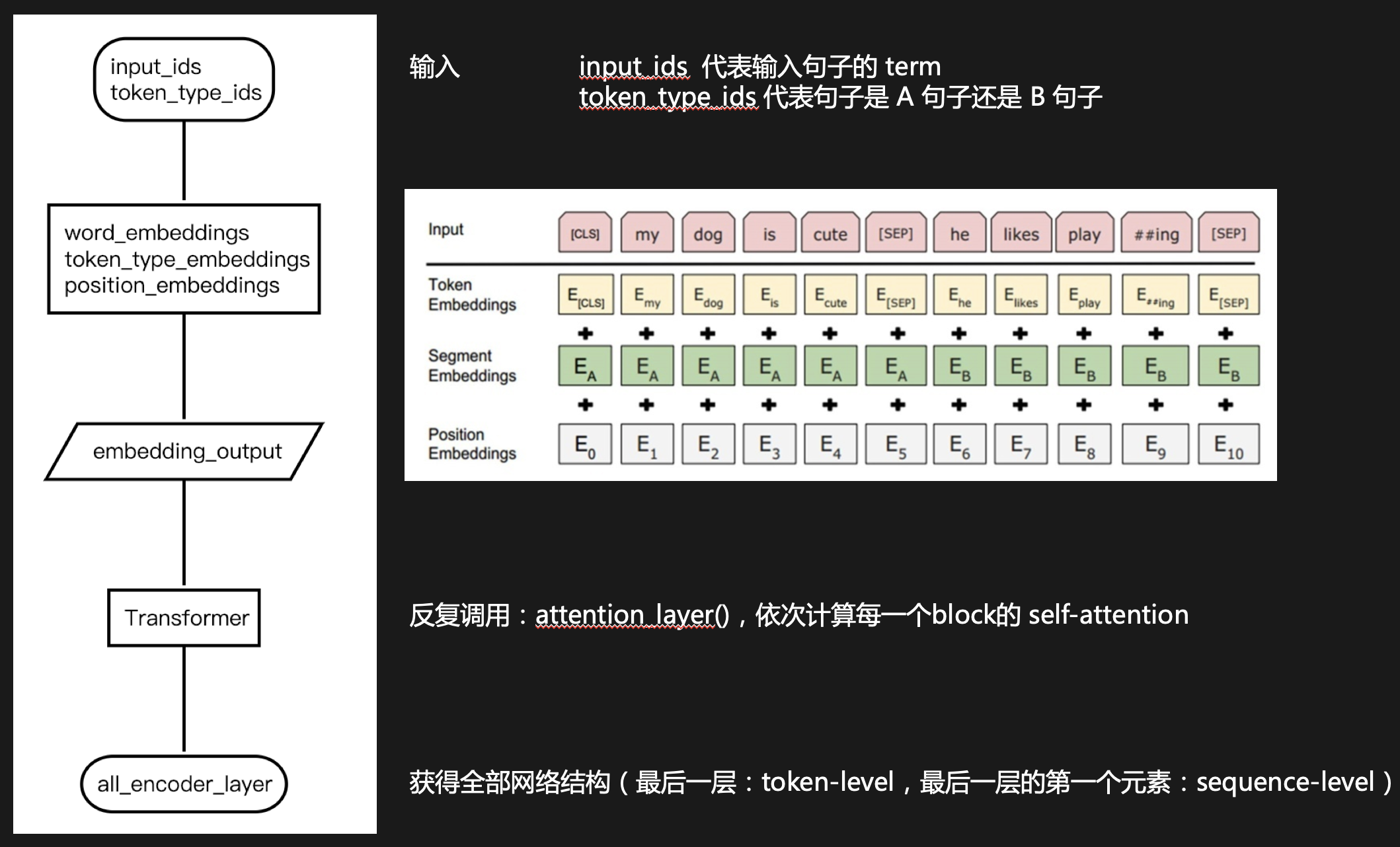
输入特征对象
模型接受最小输入形式如下(包括4个特征向量组成的tensor):
"input_ids":np.zeros((350), dtype=int).tolist(),
"input_mask":np.zeros((350), dtype=int).tolist(),
"segment_ids":np.zeros((350), dtype=int).tolist(),
"label_ids":[0]
因此,首先通过tokenization.py和vocab.txt,将原始文本中每个词语转化成input_ids,即原始词语在语料库中的ID编码,input_ids大于max_seq_length则截短,小于max_seq_length则补充0。
Embedding结构
主要由:word embedding + segment embedding + position embedding 三部分组成(参见modeling.py),如下:
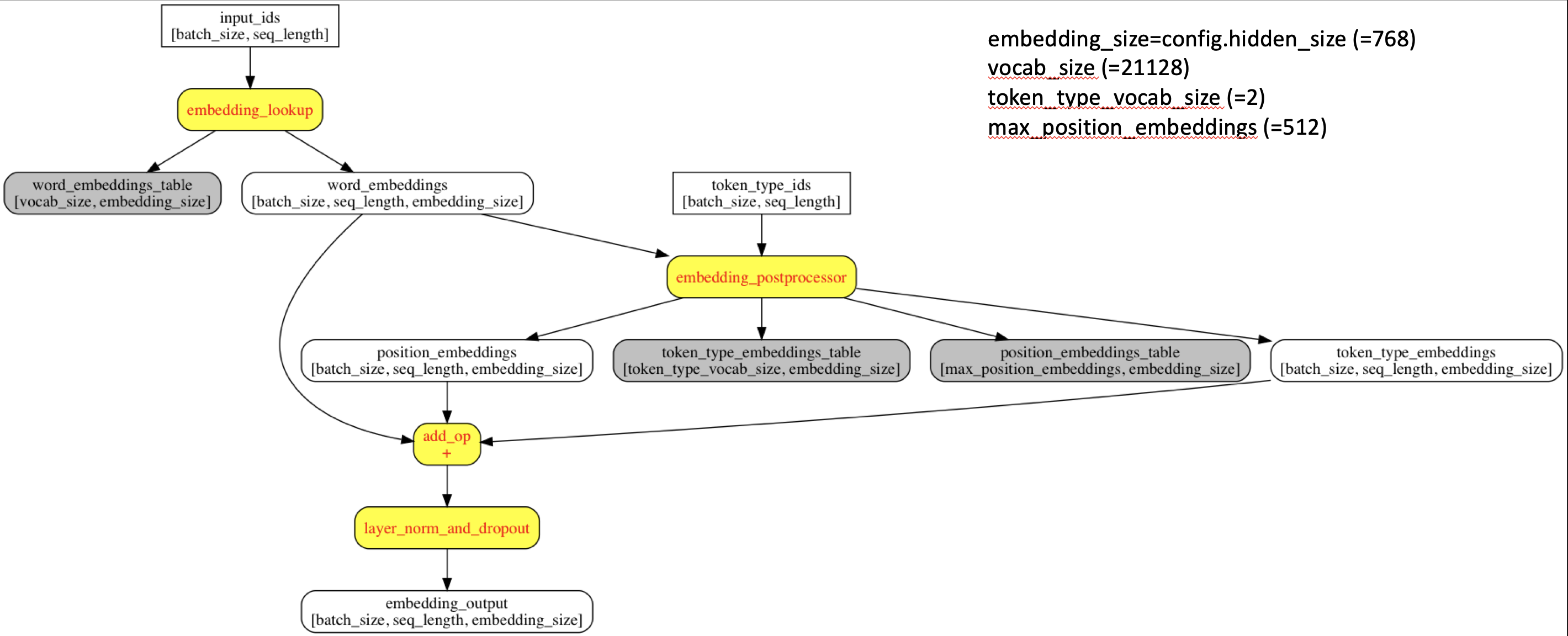
生成word embedding
用于将输入的原始文本,转化成word embedding,维度为 [batch_size, seq_length, embedding_size]。
# *** 从vocab中获取input_ids([batch_size, seq_length])对应的word_embeddings
# *** output1: [batch_size, seq_length, embedding_size]的word_embeddings
# *** output2: [vocab_size, embedding_size]的全量embedding_table
def embedding_lookup(input_ids,
vocab_size,
embedding_size=128,
initializer_range=0.02,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=False):
"""Looks up words embeddings for id tensor.
Args:
input_ids: int32 Tensor of shape [batch_size, seq_length] containing word
ids.
vocab_size: int. Size of the embedding vocabulary.
embedding_size: int. Width of the word embeddings.
initializer_range: float. Embedding initialization range.
word_embedding_name: string. Name of the embedding table.
use_one_hot_embeddings: bool. If True, use one-hot method for word
embeddings. If False, use `tf.nn.embedding_lookup()`. One hot is better
for TPUs.
Returns:
float Tensor of shape [batch_size, seq_length, embedding_size].
"""
# This function assumes that the input is of shape [batch_size, seq_length,
# num_inputs].
#
# If the input is a 2D tensor of shape [batch_size, seq_length], we
# reshape to [batch_size, seq_length, 1].
if input_ids.shape.ndims == 2:
input_ids = tf.expand_dims(input_ids, axis=[-1])
embedding_table = tf.get_variable(
name=word_embedding_name,
shape=[vocab_size, embedding_size],
initializer=create_initializer(initializer_range))
if use_one_hot_embeddings:
flat_input_ids = tf.reshape(input_ids, [-1]) # *** reshape to 1D of [batch_size * seq_length]
one_hot_input_ids = tf.one_hot(flat_input_ids, depth=vocab_size) # *** [batch_size * seq_length, vocab_size]
output = tf.matmul(one_hot_input_ids, embedding_table) # *** [batch_size * seq_length, embedding_size]
else:
#according to id from input_ids,find tensor of embedding_table
output = tf.nn.embedding_lookup(embedding_table, input_ids) # *** [batch_size * seq_length, embedding_size]
input_shape = get_shape_list(input_ids) # *** input_ids is [batch_size, seq_length, 1]
output = tf.reshape(output,
input_shape[0:-1] + [input_shape[-1] * embedding_size]) # *** [batch_size, seq_length, embedding_size]
return (output, embedding_table)
生成segment embedding和position embedding
生成与word embedding 相同维度的segment embedding和position embedding,并将3个embedding进行合并,形成最终的embedding张量,维度为 [batch_size, seq_length, embedding_size],用于Transformer的输入。
# *** 获取token_type_embeddings和position_embeddings,并与word_embeddings叠加,
# *** 生成整体embedding_output [batch_size, seq_length, embedding_size]
def embedding_postprocessor(input_tensor,
use_token_type=False,
token_type_ids=None,
token_type_vocab_size=16,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=0.02,
max_position_embeddings=512,
dropout_prob=0.1):
"""Performs various post-processing on a word embedding tensor.
Args:
input_tensor: float Tensor of shape [batch_size, seq_length,
embedding_size].
use_token_type: bool. Whether to add embeddings for `token_type_ids`.
token_type_ids: (optional) int32 Tensor of shape [batch_size, seq_length].
Must be specified if `use_token_type` is True.
token_type_vocab_size: int. The vocabulary size of `token_type_ids`.
token_type_embedding_name: string. The name of the embedding table variable
for token type ids.
use_position_embeddings: bool. Whether to add position embeddings for the
position of each token in the sequence.
position_embedding_name: string. The name of the embedding table variable
for positional embeddings.
initializer_range: float. Range of the weight initialization.
max_position_embeddings: int. Maximum sequence length that might ever be
used with this model. This can be longer than the sequence length of
input_tensor, but cannot be shorter.
dropout_prob: float. Dropout probability applied to the final output tensor.
Returns:
float tensor with same shape as `input_tensor`.
Raises:
ValueError: One of the tensor shapes or input values is invalid.
"""
# *** input_shape是[batch_size, seq_length, embedding_size]
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
width = input_shape[2] # *** == embedding_size
output = input_tensor
if use_token_type:
if token_type_ids is None:
raise ValueError("`token_type_ids` must be specified if"
"`use_token_type` is True.")
# *** 生成[token_type_vocab_size, embedding_size]的token_type的embedding_table
token_type_table = tf.get_variable(
name=token_type_embedding_name,
shape=[token_type_vocab_size, width],
initializer=create_initializer(initializer_range))
# This vocab will be small so we always do one-hot here, since it is always
# faster for a small vocabulary.
# *** 由于token_type的vocab很小,所以直接用one-hot,这样能更快,这个用法和上面的embedding_lookup函数一样
flat_token_type_ids = tf.reshape(token_type_ids, [-1])
one_hot_ids = tf.one_hot(flat_token_type_ids, depth=token_type_vocab_size) # *** [batch_size * seq_length, 2]
token_type_embeddings = tf.matmul(one_hot_ids, token_type_table) # *** [batch_size * seq_length, embedding_size]
token_type_embeddings = tf.reshape(token_type_embeddings,
[batch_size, seq_length, width]) # *** [batch_size, seq_length, embedding_size]
output += token_type_embeddings
if use_position_embeddings:
assert_op = tf.assert_less_equal(seq_length, max_position_embeddings) # *** 如果x>y就抛出异常
with tf.control_dependencies([assert_op]):
# *** 生成[max_position_embeddings, embedding_size]的position的embedding_table
full_position_embeddings = tf.get_variable(
name=position_embedding_name,
shape=[max_position_embeddings, width],
initializer=create_initializer(initializer_range))
# Since the position embedding table is a learned variable, we create it
# using a (long) sequence length `max_position_embeddings`. The actual
# sequence length might be shorter than this, for faster training of
# tasks that do not have long sequences.
#
# So `full_position_embeddings` is effectively an embedding table
# for position [0, 1, 2, ..., max_position_embeddings-1], and the current
# sequence has positions [0, 1, 2, ... seq_length-1], so we can just
# perform a slice.
position_embeddings = tf.slice(full_position_embeddings, [0, 0],
[seq_length, -1])
num_dims = len(output.shape.as_list())
# Only the last two dimensions are relevant (`seq_length` and `width`), so
# we broadcast among the first dimensions, which is typically just
# the batch size.
position_broadcast_shape = []
for _ in range(num_dims - 2):
position_broadcast_shape.append(1)
position_broadcast_shape.extend([seq_length, width])
position_embeddings = tf.reshape(position_embeddings,
position_broadcast_shape)
output += position_embeddings
output = layer_norm_and_dropout(output, dropout_prob)
return output
输入input_ids的mask
针对input_ids的输入,选择被mask的单词位置。
Transformer模型构建
Transformer模型是通过多层multi-heads Attension组成的,因此分为2个部分:单个self-attention构建 + 多个self-attention组成Transformer(参见 modeling.py)。
sequence_output: 做token-level的应用(eg,. 实体识别)
pooled_output: 做one or pair sequence-level的应用(eg., 语义分类)
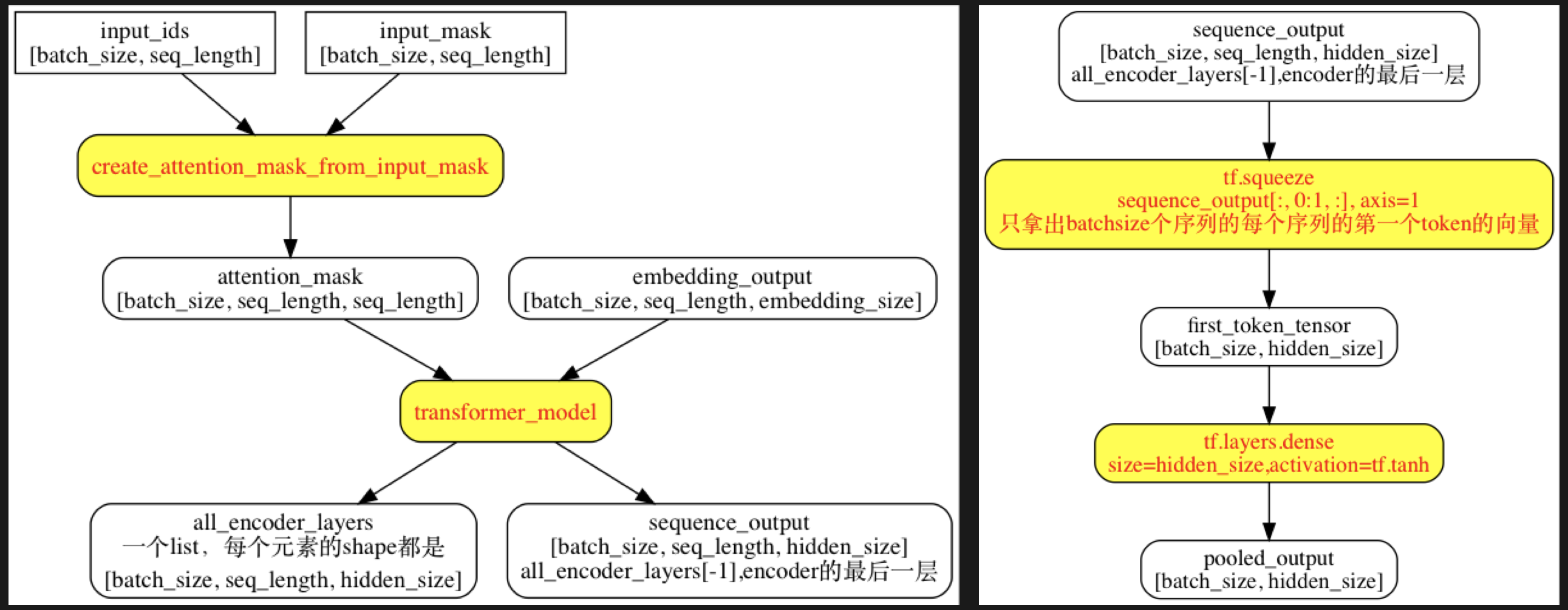
构建Attention
用于构建单个self-attention模型,主要通过构建Query、Key和Value来实现不同输入的权重贡献。
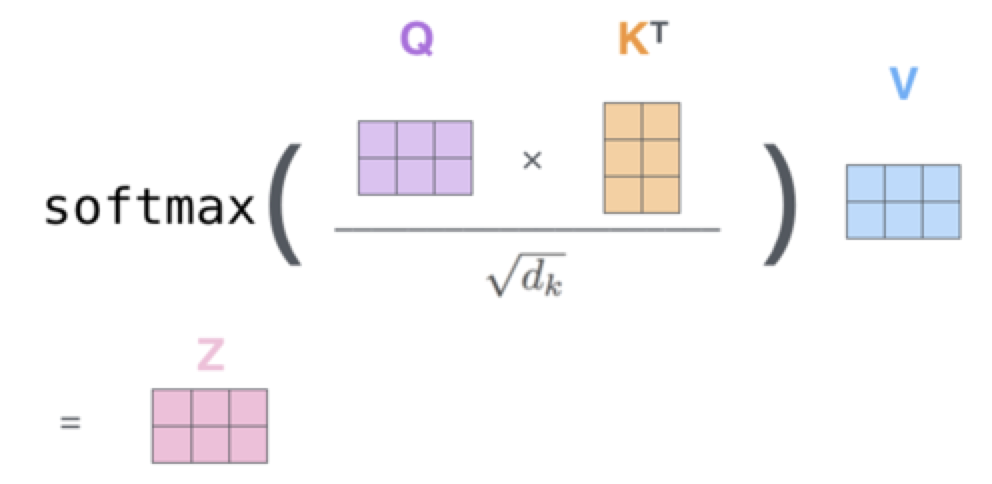
# *** 计算multi-headed attention (当from_tensor==to_tensor时,为self-attention)
def attention_layer(from_tensor,
to_tensor,
attention_mask=None,
num_attention_heads=1,
size_per_head=512,
query_act=None,
key_act=None,
value_act=None,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
do_return_2d_tensor=False,
batch_size=None,
from_seq_length=None,
to_seq_length=None):
"""Performs multi-headed attention from `from_tensor` to `to_tensor`.
This is an implementation of multi-headed attention based on "Attention
is all you Need". If `from_tensor` and `to_tensor` are the same, then
this is self-attention. Each timestep in `from_tensor` attends to the
corresponding sequence in `to_tensor`, and returns a fixed-with vector.
This function first projects `from_tensor` into a "query" tensor and
`to_tensor` into "key" and "value" tensors. These are (effectively) a list
of tensors of length `num_attention_heads`, where each tensor is of shape
[batch_size, seq_length, size_per_head].
Then, the query and key tensors are dot-producted and scaled. These are
softmaxed to obtain attention probabilities. The value tensors are then
interpolated by these probabilities, then concatenated back to a single
tensor and returned.
In practice, the multi-headed attention are done with transposes and
reshapes rather than actual separate tensors.
Args:
from_tensor: float Tensor of shape [batch_size, from_seq_length,
from_width].
to_tensor: float Tensor of shape [batch_size, to_seq_length, to_width].
attention_mask: (optional) int32 Tensor of shape [batch_size,
from_seq_length, to_seq_length]. The values should be 1 or 0. The
attention scores will effectively be set to -infinity for any positions in
the mask that are 0, and will be unchanged for positions that are 1.
num_attention_heads: int. Number of attention heads.
size_per_head: int. Size of each attention head.
query_act: (optional) Activation function for the query transform.
key_act: (optional) Activation function for the key transform.
value_act: (optional) Activation function for the value transform.
attention_probs_dropout_prob: (optional) float. Dropout probability of the
attention probabilities.
initializer_range: float. Range of the weight initializer.
do_return_2d_tensor: bool. If True, the output will be of shape [batch_size
* from_seq_length, num_attention_heads * size_per_head]. If False, the
output will be of shape [batch_size, from_seq_length, num_attention_heads
* size_per_head].
batch_size: (Optional) int. If the input is 2D, this might be the batch size
of the 3D version of the `from_tensor` and `to_tensor`.
from_seq_length: (Optional) If the input is 2D, this might be the seq length
of the 3D version of the `from_tensor`.
to_seq_length: (Optional) If the input is 2D, this might be the seq length
of the 3D version of the `to_tensor`.
Returns:
float Tensor of shape [batch_size, from_seq_length,
num_attention_heads * size_per_head]. (If `do_return_2d_tensor` is
true, this will be of shape [batch_size * from_seq_length,
num_attention_heads * size_per_head]).
Raises:
ValueError: Any of the arguments or tensor shapes are invalid.
"""
def transpose_for_scores(input_tensor, batch_size, num_attention_heads,
seq_length, width):
output_tensor = tf.reshape(
input_tensor, [batch_size, seq_length, num_attention_heads, width])
output_tensor = tf.transpose(output_tensor, [0, 2, 1, 3])
return output_tensor
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
to_shape = get_shape_list(to_tensor, expected_rank=[2, 3])
if len(from_shape) != len(to_shape):
raise ValueError(
"The rank of `from_tensor` must match the rank of `to_tensor`.")
if len(from_shape) == 3:
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_seq_length = to_shape[1]
elif len(from_shape) == 2:
if (batch_size is None or from_seq_length is None or to_seq_length is None):
raise ValueError(
"When passing in rank 2 tensors to attention_layer, the values "
"for `batch_size`, `from_seq_length`, and `to_seq_length` "
"must all be specified.")
# Scalar dimensions referenced here:
# B = batch size (number of sequences)
# F = `from_tensor` sequence length
# T = `to_tensor` sequence length
# N = `num_attention_heads`
# H = `size_per_head`
# *** from_tensor_2d([batch*max_sequence_length, hidden_size])
# *** to_tensor_2d([batch*max_sequence_length, hidden_size])
from_tensor_2d = reshape_to_matrix(from_tensor)
to_tensor_2d = reshape_to_matrix(to_tensor)
# `query_layer` = [B*F, N*H]
# *** query_layer([batch*max_sequence_length, num_atention_heads*size_per_head])
query_layer = tf.layers.dense(
from_tensor_2d,
num_attention_heads * size_per_head,
activation=query_act,
name="query",
kernel_initializer=create_initializer(initializer_range))
# `key_layer` = [B*T, N*H]
# *** key_layer([batch*max_sequence_length, num_atention_heads*size_per_head])
key_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=key_act,
name="key",
kernel_initializer=create_initializer(initializer_range))
# `value_layer` = [B*T, N*H]
# *** value_layer([batch*max_sequence_length, num_atention_heads*size_per_head])
value_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=value_act,
name="value",
kernel_initializer=create_initializer(initializer_range))
# `query_layer` = [B, N, F, H]
query_layer = transpose_for_scores(query_layer, batch_size,
num_attention_heads, from_seq_length,
size_per_head)
# `key_layer` = [B, N, T, H]
key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads,
to_seq_length, size_per_head)
# Take the dot product between "query" and "key" to get the raw
# attention scores.
# `attention_scores` = [B, N, F, T]
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True) # *** query * key
attention_scores = tf.multiply(attention_scores,
1.0 / math.sqrt(float(size_per_head))) # *** scale
if attention_mask is not None:
# `attention_mask` = [B, 1, F, T]
# *** attention_mask is [batch_size, from_seq_length, to_seq_length]
attention_mask = tf.expand_dims(attention_mask, axis=[1])
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
attention_scores += adder
# Normalize the attention scores to probabilities.
# `attention_probs` = [B, N, F, T]
attention_probs = tf.nn.softmax(attention_scores) # *** get weight according to softmax
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = dropout(attention_probs, attention_probs_dropout_prob)
# `value_layer` = [B, T, N, H]
value_layer = tf.reshape(
value_layer,
[batch_size, to_seq_length, num_attention_heads, size_per_head])
# `value_layer` = [B, N, T, H]
value_layer = tf.transpose(value_layer, [0, 2, 1, 3])
# `context_layer` = [B, N, F, H]
context_layer = tf.matmul(attention_probs, value_layer) # *** weight * value
# `context_layer` = [B, F, N, H]
context_layer = tf.transpose(context_layer, [0, 2, 1, 3])
if do_return_2d_tensor:
# `context_layer` = [B*F, N*V]
context_layer = tf.reshape(
context_layer,
[batch_size * from_seq_length, num_attention_heads * size_per_head])
else:
# `context_layer` = [B, F, N*V]
context_layer = tf.reshape(
context_layer,
[batch_size, from_seq_length, num_attention_heads * size_per_head])
return context_layer
构建Transformer模型
用于构建12层attention组成的Transformer模型,注意feed forward处存在2处线性变换(“H to 4H” and “4H to H”,H is hidden_size)。
# 构建包括12层attention的transformer模型
def transformer_model(input_tensor,
attention_mask=None,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
intermediate_act_fn=gelu,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
do_return_all_layers=False):
"""Multi-headed, multi-layer Transformer from "Attention is All You Need".
This is almost an exact implementation of the original Transformer encoder.
See the original paper:
https://arxiv.org/abs/1706.03762
Also see:
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py
Args:
input_tensor: float Tensor of shape [batch_size, seq_length, hidden_size].
attention_mask: (optional) int32 Tensor of shape [batch_size, seq_length,
seq_length], with 1 for positions that can be attended to and 0 in
positions that should not be.
hidden_size: int. Hidden size of the Transformer.
num_hidden_layers: int. Number of layers (blocks) in the Transformer.
num_attention_heads: int. Number of attention heads in the Transformer.
intermediate_size: int. The size of the "intermediate" (a.k.a., feed
forward) layer.
intermediate_act_fn: function. The non-linear activation function to apply
to the output of the intermediate/feed-forward layer.
hidden_dropout_prob: float. Dropout probability for the hidden layers.
attention_probs_dropout_prob: float. Dropout probability of the attention
probabilities.
initializer_range: float. Range of the initializer (stddev of truncated
normal).
do_return_all_layers: Whether to also return all layers or just the final
layer.
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size], the final
hidden layer of the Transformer.
Raises:
ValueError: A Tensor shape or parameter is invalid.
"""
if hidden_size % num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
attention_head_size = int(hidden_size / num_attention_heads)
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
input_width = input_shape[2]
# The Transformer performs sum residuals on all layers so the input needs
# to be the same as the hidden size.
if input_width != hidden_size:
raise ValueError("The width of the input tensor (%d) != hidden size (%d)" %
(input_width, hidden_size))
# We keep the representation as a 2D tensor to avoid re-shaping it back and
# forth from a 3D tensor to a 2D tensor. Re-shapes are normally free on
# the GPU/CPU but may not be free on the TPU, so we want to minimize them to
# help the optimizer.
# *** 为了减少representation在2D和3D之间的变换过程,所以在处理过程中保持2D的状态
# *** 这是因为在GPU/CPU上reshape比较方便,但在TPU上并不方便
# *** input_tensor([batch_size, max_sequence_length, hidden_size])
# *** prev_output([batch_size*max_sequence_length, hidden_size])
prev_output = reshape_to_matrix(input_tensor)
all_layer_outputs = []
for layer_idx in range(num_hidden_layers):
with tf.variable_scope("layer_%d" % layer_idx):
layer_input = prev_output
with tf.variable_scope("attention"):
attention_heads = []
with tf.variable_scope("self"):
attention_head = attention_layer(
from_tensor=layer_input,
to_tensor=layer_input,
attention_mask=attention_mask,
num_attention_heads=num_attention_heads,
size_per_head=attention_head_size,
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
attention_heads.append(attention_head)
# *** attention_output is [batch_size * from_seq_length, num_attention_heads * size_per_head]
# *** thus, attention_output is [batch_size * from_seq_length, hidden_size]
attention_output = None
# *** one head
if len(attention_heads) == 1:
attention_output = attention_heads[0]
else:
# *** multiple heads
# In the case where we have other sequences, we just concatenate
# them to the self-attention head before the projection.
attention_output = tf.concat(attention_heads, axis=-1)
# *** add & norm
# Run a linear projection of `hidden_size` then add a residual
# with `layer_input`.
with tf.variable_scope("output"):
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range)) # *** add multi-heads attention的线性变换
attention_output = dropout(attention_output, hidden_dropout_prob)
attention_output = layer_norm(attention_output + layer_input) # *** add residual and layernrom
# *** feed forward
# *** intermediate_output ([batch*max_sequence_length, intermediate_size])
# The activation is only applied to the "intermediate" hidden layer.
with tf.variable_scope("intermediate"):
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range)) # *** convert hidden_size to intermediate_size
# *** add & norm
# *** layer_output ([batch*max_sequence_length, hidden_size])
# Down-project back to `hidden_size` then add the residual.
with tf.variable_scope("output"):
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range)) # *** convert intermediate_size to hidden_size
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output) # *** add residual
prev_output = layer_output
all_layer_outputs.append(layer_output)
# *** 将输出reshape成和input_shape一样的shape,即[batch_size, seq_length, hidden_size]
if do_return_all_layers:
final_outputs = []
for layer_output in all_layer_outputs:
final_output = reshape_from_matrix(layer_output, input_shape)
final_outputs.append(final_output) # *** all layer reshape
return final_outputs
else:
final_output = reshape_from_matrix(prev_output, input_shape) # *** final layer reshape
return final_output
初步构建BERT模型
基于Transformer模型,构建出BERT模型,输出为BERT模型的结构和参数。
class BertModel(object):
"""BERT model ("Bidirectional Embedding Representations from a Transformer").
Example usage:
```python
# Already been converted into WordPiece token ids
input_ids = tf.constant([[31, 51, 99], [15, 5, 0]])
input_mask = tf.constant([[1, 1, 1], [1, 1, 0]])
token_type_ids = tf.constant([[0, 0, 1], [0, 2, 0]])
config = modeling.BertConfig(vocab_size=32000, hidden_size=512,
num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
model = modeling.BertModel(config=config, is_training=True,
input_ids=input_ids, input_mask=input_mask, token_type_ids=token_type_ids)
label_embeddings = tf.get_variable(...)
pooled_output = model.get_pooled_output()
logits = tf.matmul(pooled_output, label_embeddings)
...
"""
def __init__(self,
config,
is_training,
input_ids,
input_mask=None,
token_type_ids=None,
use_one_hot_embeddings=True,
scope=None):
"""Constructor for BertModel.
Args:
config: `BertConfig` instance.
is_training: bool. rue for training model, false for eval model. Controls
whether dropout will be applied.
input_ids: int32 Tensor of shape [batch_size, seq_length].
input_mask: (optional) int32 Tensor of shape [batch_size, seq_length].
token_type_ids: (optional) int32 Tensor of shape [batch_size, seq_length].
use_one_hot_embeddings: (optional) bool. Whether to use one-hot word
embeddings or tf.embedding_lookup() for the word embeddings. On the TPU,
it is must faster if this is True, on the CPU or GPU, it is faster if
this is False.
scope: (optional) variable scope. Defaults to "bert".
Raises:
ValueError: The config is invalid or one of the input tensor shapes
is invalid.
"""
config = copy.deepcopy(config)
if not is_training:
config.hidden_dropout_prob = 0.0
config.attention_probs_dropout_prob = 0.0
input_shape = get_shape_list(input_ids, expected_rank=2) #256*512
batch_size = input_shape[0]
seq_length = input_shape[1]
if input_mask is None:
input_mask = tf.ones(shape=[batch_size, seq_length], dtype=tf.int32)
if token_type_ids is None:
token_type_ids = tf.zeros(shape=[batch_size, seq_length], dtype=tf.int32)
with tf.variable_scope(scope, default_name="bert"):
with tf.variable_scope("embeddings"):
# Perform embedding lookup on the word ids.
(self.embedding_output, self.embedding_table) = embedding_lookup(
input_ids=input_ids,
vocab_size=config.vocab_size,
embedding_size=config.hidden_size,
initializer_range=config.initializer_range,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=use_one_hot_embeddings)
# Add positional embeddings and token type embeddings, then layer
# normalize and perform dropout.
self.embedding_output = embedding_postprocessor(
input_tensor=self.embedding_output,
use_token_type=True,
token_type_ids=token_type_ids,
token_type_vocab_size=config.type_vocab_size,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=config.initializer_range,
max_position_embeddings=config.max_position_embeddings,
dropout_prob=config.hidden_dropout_prob)
with tf.variable_scope("encoder"):
# This converts a 2D mask of shape [batch_size, seq_length] to a 3D
# mask of shape [batch_size, seq_length, seq_length] which is used
# for the attention scores.
attention_mask = create_attention_mask_from_input_mask(
input_ids, input_mask)
# Run the stacked transformer.
# `all_encoder_layers` is one list
# `sequence_output` shape = [batch_size, seq_length, hidden_size].
self.all_encoder_layers = transformer_model(
input_tensor=self.embedding_output,
attention_mask=attention_mask,
hidden_size=config.hidden_size,
num_hidden_layers=config.num_hidden_layers,
num_attention_heads=config.num_attention_heads,
intermediate_size=config.intermediate_size,
intermediate_act_fn=get_activation(config.hidden_act),
hidden_dropout_prob=config.hidden_dropout_prob,
attention_probs_dropout_prob=config.attention_probs_dropout_prob,
initializer_range=config.initializer_range,
do_return_all_layers=True)
self.sequence_output = self.all_encoder_layers[-1]
# The "pooler" converts the encoded sequence tensor of shape
# [batch_size, seq_length, hidden_size] to a tensor of shape
# [batch_size, hidden_size]. This is necessary for segment-level
# (or segment-pair-level) classification tasks where we need a fixed
# dimensional representation of the segment.
with tf.variable_scope("pooler"):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token. We assume that this has been pre-trained
# *** 只拿出batchsize个序列的每个序列的第一个token的向量(下面的[:,0:1,:])出来
# *** 从[batch_size, seq_length, hidden_size]变成了[batch_size, hidden_size]
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)
self.pooled_output = tf.layers.dense(
first_token_tensor,
config.hidden_size,
activation=tf.tanh,
kernel_initializer=create_initializer(config.initializer_range))
# *** return [batch_size, hidden_size]
def get_pooled_output(self):
return self.pooled_output
# *** return [batch_size, seq_length, hidden_size]
def get_sequence_output(self):
"""Gets final hidden layer of encoder.
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size] corresponding
to the final hidden of the transformer encoder.
"""
return self.sequence_output
def get_all_encoder_layers(self):
return self.all_encoder_layers
def get_embedding_output(self):
"""Gets output of the embedding lookup (i.e., input to the transformer).
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size] corresponding
to the output of the embedding layer, after summing the word
embeddings with the positional embeddings and the token type embeddings,
then performing layer normalization. This is the input to the transformer.
"""
return self.embedding_output
def get_embedding_table(self):
return self.embedding_table
预训练模型的Fine-tune
通过重新训练BERT模型的最后一层全连接层权重,来实现模型在自有数据上的fine-tune(参见 run_classifier.py)。
添加自有数据处理函数
根据代码中提供的4个数据集的数据处理方式,修改对自有数据的处理方式,如下:
## new add
class SelfProcessor(DataProcessor):
"""Processor for the myself data set."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["0", "1"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
# Only the test set has a header
if set_type == "test" and i == 0:
continue
guid = "%s-%s" % (set_type, i)
if set_type == "test":
text_a = tokenization.convert_to_unicode(line[2]) #test set: 'id1','id2','ocr','url'
label = "0"
else:
text_a = tokenization.convert_to_unicode(line[2]) #train set: 'id1','id2','ocr','url','label'
label = tokenization.convert_to_unicode(line[4])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
生成特征对象
用于生成token对应的包含4个特征向量的对象(input_ids、input_mask、segment_ids、label_ids),如下:
# *** 生成token对应的feature对象
def convert_single_example(ex_index, example, label_list, max_seq_length,
tokenizer):
"""Converts a single `InputExample` into a single `InputFeatures`."""
label_map = {}
for (i, label) in enumerate(label_list):
label_map[label] = i
tokens_a = tokenizer.tokenize(example.text_a)
tokens_b = None
if example.text_b:
tokens_b = tokenizer.tokenize(example.text_b)
if tokens_b:
# Modifies `tokens_a` and `tokens_b` in place so that the total
# length is less than the specified length.
# Account for [CLS], [SEP], [SEP] with "- 3"
_truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)
else:
# Account for [CLS] and [SEP] with "- 2"
if len(tokens_a) > max_seq_length - 2:
tokens_a = tokens_a[0:(max_seq_length - 2)]
# The convention in BERT is:
# (a) For sequence pairs:
# tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
# type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1
# (b) For single sequences:
# tokens: [CLS] the dog is hairy . [SEP]
# type_ids: 0 0 0 0 0 0 0
#
# Where "type_ids" are used to indicate whether this is the first
# sequence or the second sequence. The embedding vectors for `type=0` and
# `type=1` were learned during pre-training and are added to the wordpiece
# embedding vector (and position vector). This is not *strictly* necessary
# since the [SEP] token unambiguously separates the sequences, but it makes
# it easier for the model to learn the concept of sequences.
#
# For classification tasks, the first vector (corresponding to [CLS]) is
# used as as the "sentence vector". Note that this only makes sense because
# the entire model is fine-tuned.
tokens = []
segment_ids = []
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
if tokens_b:
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
tokens.append("[SEP]")
segment_ids.append(1)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# The mask has 1 for real tokens and 0 for padding tokens. Only real
# tokens are attended to.
input_mask = [1] * len(input_ids)
# Zero-pad up to the sequence length.
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
label_id = label_map[example.label]
if ex_index < 5:
tf.logging.info("*** Example ***")
tf.logging.info("guid: %s" % (example.guid))
tf.logging.info("tokens: %s" % " ".join(
[tokenization.printable_text(x) for x in tokens]))
tf.logging.info("input_ids: %s" % " ".join([str(x) for x in input_ids]))
tf.logging.info("input_mask: %s" % " ".join([str(x) for x in input_mask]))
tf.logging.info("segment_ids: %s" % " ".join([str(x) for x in segment_ids]))
tf.logging.info("label: %s (id = %d)" % (example.label, label_id))
feature = InputFeatures(
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
label_id=label_id)
return feature
生成tfrecord文件
将生成的特征对象,转换成tfrecord文件,并写出到磁盘。
# *** 将上述feature对象转换成tfrecord文件,并写出
def file_based_convert_examples_to_features(
examples, label_list, max_seq_length, tokenizer, output_file):
"""Convert a set of `InputExample`s to a TFRecord file."""
writer = tf.python_io.TFRecordWriter(output_file)
for (ex_index, example) in enumerate(examples):
if ex_index % 10000 == 0:
tf.logging.info("Writing example %d of %d" % (ex_index, len(examples)))
feature = convert_single_example(ex_index, example, label_list,
max_seq_length, tokenizer)
def create_int_feature(values):
f = tf.train.Feature(int64_list=tf.train.Int64List(value=list(values)))
return f
features = collections.OrderedDict()
features["input_ids"] = create_int_feature(feature.input_ids)
features["input_mask"] = create_int_feature(feature.input_mask)
features["segment_ids"] = create_int_feature(feature.segment_ids)
features["label_ids"] = create_int_feature([feature.label_id])
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
writer.write(tf_example.SerializeToString())
Tfrecord文件解析
对tfrecord文件进行解析,并返回input_fn()方法作为后续TPUEstimator的输入参数。
# *** 对tfrecord文件进行解析
def file_based_input_fn_builder(input_file, seq_length, is_training,
drop_remainder):
"""Creates an `input_fn` closure to be passed to TPUEstimator."""
name_to_features = {
"input_ids": tf.FixedLenFeature([seq_length], tf.int64),
"input_mask": tf.FixedLenFeature([seq_length], tf.int64),
"segment_ids": tf.FixedLenFeature([seq_length], tf.int64),
"label_ids": tf.FixedLenFeature([], tf.int64),
}
def _decode_record(record, name_to_features):
"""Decodes a record to a TensorFlow example."""
example = tf.parse_single_example(record, name_to_features) # *** 解析函数
# tf.Example only supports tf.int64, but the TPU only supports tf.int32.
# So cast all int64 to int32.
for name in list(example.keys()):
t = example[name]
if t.dtype == tf.int64:
t = tf.to_int32(t)
example[name] = t
return example
def input_fn(params):
"""The actual input function."""
batch_size = params["batch_size"]
# For training, we want a lot of parallel reading and shuffling.
# For eval, we want no shuffling and parallel reading doesn't matter.
d = tf.data.TFRecordDataset(input_file)
if is_training:
d = d.repeat()
d = d.shuffle(buffer_size=100)
d = d.apply(
tf.contrib.data.map_and_batch(
lambda record: _decode_record(record, name_to_features),
batch_size=batch_size,
drop_remainder=drop_remainder))
return d
return input_fn
添加最后的全连接层
在已构建好的BERT模型上,添加一层全连接。
# *** 创建模型(在BertModel基础上,添加用于分类预测的全连接层)
def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,
labels, num_labels, use_one_hot_embeddings):
"""Creates a classification model."""
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
# In the demo, we are doing a simple classification task on the entire
# segment.
#
# If you want to use the token-level output, use model.get_sequence_output()
# instead.
output_layer = model.get_pooled_output() # *** [batch_size, hidden_size]
hidden_size = output_layer.shape[-1].value
# *** 添加模型最终的全连接层+softmax
output_weights = tf.get_variable(
"output_weights", [num_labels, hidden_size],
initializer=tf.truncated_normal_initializer(stddev=0.02))
output_bias = tf.get_variable(
"output_bias", [num_labels], initializer=tf.zeros_initializer())
with tf.variable_scope("loss"):
if is_training:
# I.e., 0.1 dropout
output_layer = tf.nn.dropout(output_layer, keep_prob=0.9)
logits = tf.matmul(output_layer, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias) # *** 全连接层
probabilities = tf.nn.softmax(logits, axis=-1) # *** 输出为值为0-1之间的向量
log_probs = tf.nn.log_softmax(logits, axis=-1)
one_hot_labels = tf.one_hot(labels, depth=num_labels, dtype=tf.float32)
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)
loss = tf.reduce_mean(per_example_loss)
return (loss, per_example_loss, logits, probabilities)
训练全连接层的最优参数
针对不同应用,通过重新训练最后全连接层的参数,实现fine-tune。
模型通过调用optimization.py的AdamWeightDecayOptimizer()方法,进行Adam梯度下降算法,获取最优参数,并返回model_fn()方法,用于TPUEstimator的参数。
# *** 已构建好模型的应用(训练新添加全连接层的最优参数-train、模型预测结果评价-eval、模型预测-test)
# *** return model_fn()
def model_fn_builder(bert_config, num_labels, init_checkpoint, learning_rate,
num_train_steps, num_warmup_steps, use_tpu,
use_one_hot_embeddings):
"""Returns `model_fn` closure for TPUEstimator."""
def model_fn(features, labels, mode, params): # pylint: disable=unused-argument
"""The `model_fn` for TPUEstimator."""
tf.logging.info("*** Features ***")
for name in sorted(features.keys()):
tf.logging.info(" name = %s, shape = %s" % (name, features[name].shape))
input_ids = features["input_ids"]
input_mask = features["input_mask"]
segment_ids = features["segment_ids"]
label_ids = features["label_ids"]
is_training = (mode == tf.estimator.ModeKeys.TRAIN)
(total_loss, per_example_loss, logits, probabilities) = create_model(
bert_config, is_training, input_ids, input_mask, segment_ids, label_ids,
num_labels, use_one_hot_embeddings)
tvars = tf.trainable_variables()
initialized_variable_names = {}
scaffold_fn = None
if init_checkpoint:
(assignment_map, initialized_variable_names
) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)
if use_tpu:
def tpu_scaffold():
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
return tf.train.Scaffold()
scaffold_fn = tpu_scaffold
else:
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
tf.logging.info("**** Trainable Variables ****")
for var in tvars:
init_string = ""
if var.name in initialized_variable_names:
init_string = ", *INIT_FROM_CKPT*"
tf.logging.info(" name = %s, shape = %s%s", var.name, var.shape,
init_string)
output_spec = None
# *** 寻找模型最后全连接层的最优参数(调用AdamWeightDecayOptimizer())
if mode == tf.estimator.ModeKeys.TRAIN:
train_op = optimization.create_optimizer(
total_loss, learning_rate, num_train_steps, num_warmup_steps, use_tpu)
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
train_op=train_op,
scaffold_fn=scaffold_fn)
elif mode == tf.estimator.ModeKeys.EVAL:
# *** 预测结果评价指标
def metric_fn(per_example_loss, label_ids, logits):
predictions = tf.argmax(logits, axis=-1, output_type=tf.int32) # *** 得到一个向量中最大值所处的位置
#predictions = tf.cast(predictions,tf.float32) # new add
accuracy = tf.metrics.accuracy(label_ids, predictions)
loss = tf.metrics.mean(per_example_loss)
return {
"eval_accuracy": accuracy,
"eval_loss": loss,
}
eval_metrics = (metric_fn, [per_example_loss, label_ids, logits])
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
eval_metrics=eval_metrics,
scaffold_fn=scaffold_fn)
else:
# *** 结果预测
'''
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode, predictions=probabilities, scaffold_fn=scaffold_fn)
'''
# used for savedmodel
# Generate Predictions
# v15 -- predict (this is work!)
predictions = tf.argmax(probabilities, axis=-1, output_type=tf.int32) #logits-->probabilities
export_outputs={'classes': tf.estimator.export.PredictOutput(
{"probabilities": probabilities, "classid": predictions})}
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode, predictions=probabilities, scaffold_fn=scaffold_fn, export_outputs=export_outputs)
'''
# v13 -- classify
predictions = tf.argmax(probabilities, axis=-1, output_type=tf.int32)
export_outputs = {
'classes': tf.estimator.export.ClassificationOutput(
scores=probabilities,
classes=tf.as_string(predictions))
}
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode, predictions=probabilities, scaffold_fn=scaffold_fn, export_outputs=export_outputs)
'''
return output_spec
return model_fn
预训练模型的多任务学习
通过叠加单任务的损失函数,形成多任务学习的损失函数,通过梯度下降算法,完成多任务学习的训练(参见 run_pretraining.py):

def model_fn_builder(bert_config, init_checkpoint, learning_rate,
num_train_steps, num_warmup_steps, use_tpu,
use_one_hot_embeddings):
"""Returns `model_fn` closure for TPUEstimator."""
def model_fn(features, labels, mode, params): # pylint: disable=unused-argument
"""The `model_fn` for TPUEstimator."""
tf.logging.info("*** Features ***")
for name in sorted(features.keys()):
tf.logging.info(" name = %s, shape = %s" % (name, features[name].shape))
input_ids = features["input_ids"]
input_mask = features["input_mask"]
segment_ids = features["segment_ids"]
masked_lm_positions = features["masked_lm_positions"]
masked_lm_ids = features["masked_lm_ids"]
masked_lm_weights = features["masked_lm_weights"]
next_sentence_labels = features["next_sentence_labels"]
is_training = (mode == tf.estimator.ModeKeys.TRAIN)
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
# *** task1 损失函数
(masked_lm_loss,
masked_lm_example_loss, masked_lm_log_probs) = get_masked_lm_output(
bert_config, model.get_sequence_output(), model.get_embedding_table(),
masked_lm_positions, masked_lm_ids, masked_lm_weights)
# *** task2 损失函数
(next_sentence_loss, next_sentence_example_loss,
next_sentence_log_probs) = get_next_sentence_output(
bert_config, model.get_pooled_output(), next_sentence_labels)
# *** 多任务学习的总体损失函数
total_loss = masked_lm_loss + next_sentence_loss
tvars = tf.trainable_variables()
initialized_variable_names = {}
scaffold_fn = None
if init_checkpoint:
(assignment_map, initialized_variable_names
) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)
if use_tpu:
def tpu_scaffold():
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
return tf.train.Scaffold()
scaffold_fn = tpu_scaffold
else:
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
tf.logging.info("**** Trainable Variables ****")
for var in tvars:
init_string = ""
if var.name in initialized_variable_names:
init_string = ", *INIT_FROM_CKPT*"
tf.logging.info(" name = %s, shape = %s%s", var.name, var.shape,
init_string)
output_spec = None
if mode == tf.estimator.ModeKeys.TRAIN:
train_op = optimization.create_optimizer(
total_loss, learning_rate, num_train_steps, num_warmup_steps, use_tpu)
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
train_op=train_op,
scaffold_fn=scaffold_fn)
elif mode == tf.estimator.ModeKeys.EVAL:
def metric_fn(masked_lm_example_loss, masked_lm_log_probs, masked_lm_ids,
masked_lm_weights, next_sentence_example_loss,
next_sentence_log_probs, next_sentence_labels):
"""Computes the loss and accuracy of the model."""
masked_lm_log_probs = tf.reshape(masked_lm_log_probs,
[-1, masked_lm_log_probs.shape[-1]])
masked_lm_predictions = tf.argmax(
masked_lm_log_probs, axis=-1, output_type=tf.int32)
masked_lm_example_loss = tf.reshape(masked_lm_example_loss, [-1])
masked_lm_ids = tf.reshape(masked_lm_ids, [-1])
masked_lm_weights = tf.reshape(masked_lm_weights, [-1])
masked_lm_accuracy = tf.metrics.accuracy(
labels=masked_lm_ids,
predictions=masked_lm_predictions,
weights=masked_lm_weights)
masked_lm_mean_loss = tf.metrics.mean(
values=masked_lm_example_loss, weights=masked_lm_weights)
next_sentence_log_probs = tf.reshape(
next_sentence_log_probs, [-1, next_sentence_log_probs.shape[-1]])
next_sentence_predictions = tf.argmax(
next_sentence_log_probs, axis=-1, output_type=tf.int32)
next_sentence_labels = tf.reshape(next_sentence_labels, [-1])
next_sentence_accuracy = tf.metrics.accuracy(
labels=next_sentence_labels, predictions=next_sentence_predictions)
next_sentence_mean_loss = tf.metrics.mean(
values=next_sentence_example_loss)
return {
"masked_lm_accuracy": masked_lm_accuracy,
"masked_lm_loss": masked_lm_mean_loss,
"next_sentence_accuracy": next_sentence_accuracy,
"next_sentence_loss": next_sentence_mean_loss,
}
eval_metrics = (metric_fn, [
masked_lm_example_loss, masked_lm_log_probs, masked_lm_ids,
masked_lm_weights, next_sentence_example_loss,
next_sentence_log_probs, next_sentence_labels
])
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
eval_metrics=eval_metrics,
scaffold_fn=scaffold_fn)
else:
raise ValueError("Only TRAIN and EVAL modes are supported: %s" % (mode))
return output_spec
return model_fn
特别鸣谢
http://daiwk.github.io/posts/nlp-bert-code-annotated-framework.html
http://daiwk.github.io/posts/nlp-bert-code-annotated-application.html
https://blog.csdn.net/u014108004/article/details/84142035
http://www.pianshen.com/article/4166153565/