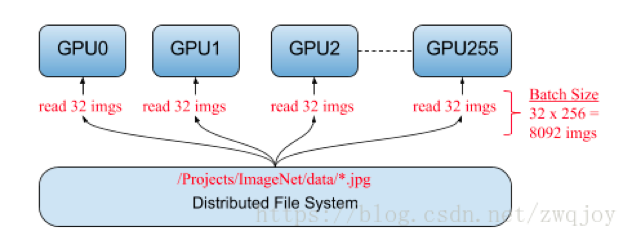
模型并行vs.数据并行
模型并行
不同 node 输入相同数据,运行模型的不同部分
- 适用模型本身很大,否则一般不会采用模型并行,因为模型层与层之间存在串行逻辑
- 或者,模型本身存在一些可以并行的单元,模型的各个部分并行于多个计算设备上
数据并行
不同 node 输入不同数据,运行相同的完整的模型
- 多个模型副本分别处理不同的训练数据,以提高整体吞吐量,是常见的分布式训练策略
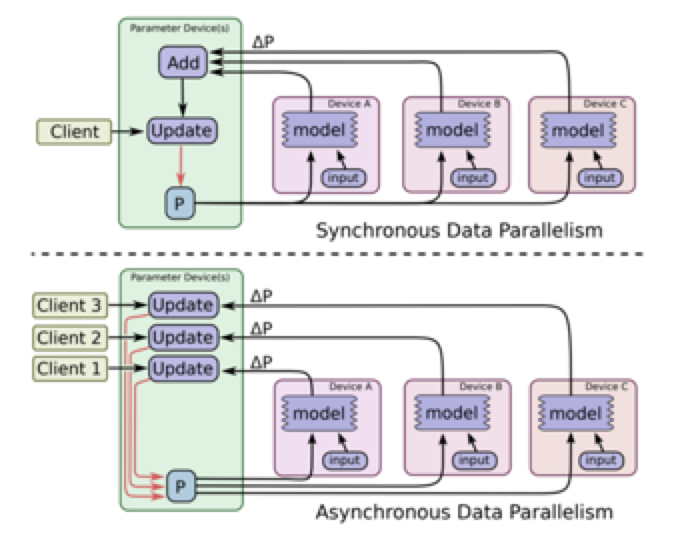
- 模型参数更新:同步(synchronous)和异步(asynchronous)
- 模型复制: in-graph复制 vs. between-graph复制
- 目前TF中常采用的是异步Between-graph
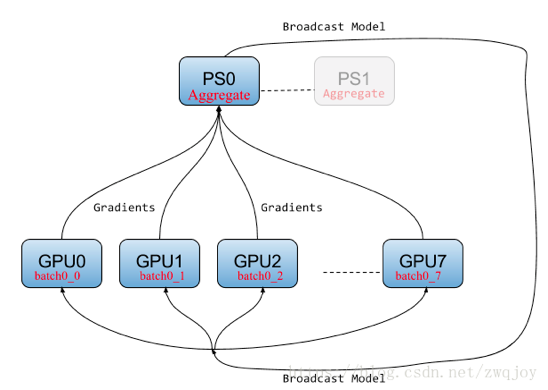
PS 架构
PS架构介绍
Parameter server 架构,是TensorFlow基础的分布式框架,将几百亿的参数分散到不同的机器上去保存和更新,解决参数存储和更新的性能问题。
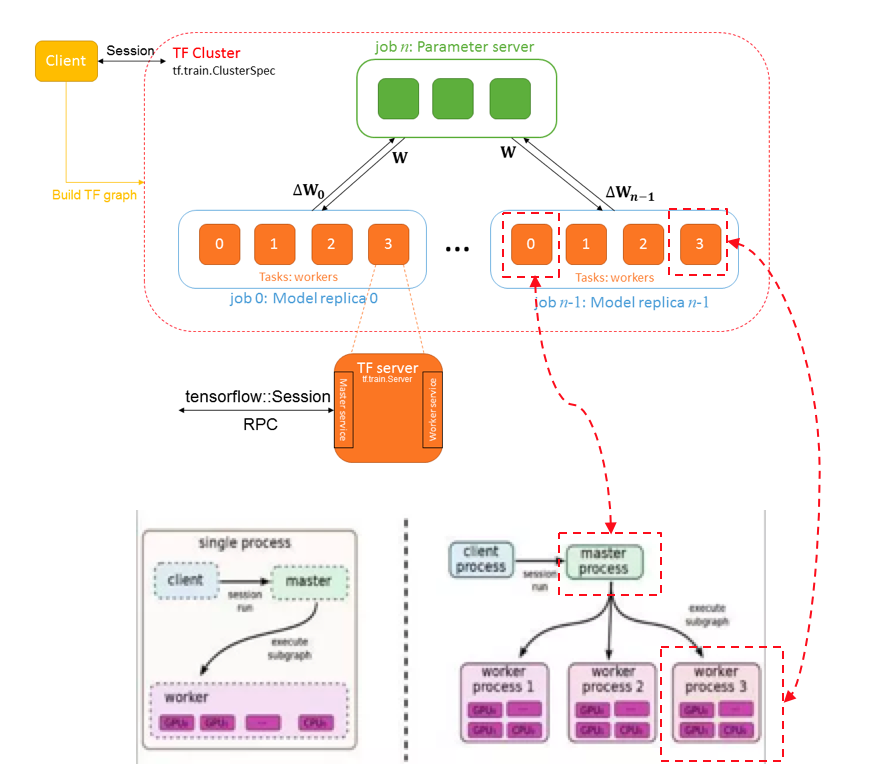
- Client通常是一个程序,用于构建tensorflow graph,通过Session与集群中的Master service进行交互。
- 参与TensorFlow分布式系统的所有节点或者设备统称为一个Cluster,被切分成多个job,每个job负责一类特定任务(比如 ps job / ps节点或者worker job/worker节点),每个job可以包含多个Task,命名: /job:ps/task:0, /job:worker/task:1 。
- 每个Task是一台独立机器,如果参数量太大,一台机器处理不了,这就要需要多个Tasks,每个Task计算一个字图(模型并行)。
- 每个Task对应一个Server , Server和Task是一一对应的,每个Server上会绑定两个Service:Master service和Worker service。
- Client通过Session连接集群中的任意一个Server的Master Service提交计算图,Master Service负责划分子图,并派发Task给Worker Service,Worker Service负责运算派发过来的Task,完成子图的运算。
- Worker job 上的Worker Service将负责梯度运算,ps job上的Worker Service将负责参数更新,Master Service将仅有一个会在需要时被用到,负责子图划分与Task派发。
同步更新 vs. 异步更新
同步更新(synchronous)
- 所有设备的mini-batch训练完成后,收集它们的梯度然后取均值,然后执行模型的一次参数更新
- 优势:loss 下降稳定
- 劣势:每一步的处理速度都取决于最慢的那个 worker
异步更新(asynchronous)
- 各个设备完成一个mini-batch训练之后,不需要等待其它节点,直接去更新模型的参数
- 优势:速度快,优化计算资源利用率
- 劣势:loss 下降不稳定
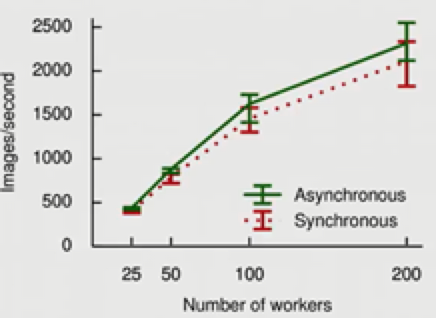
Workers从25到200(8倍),数据处理速度从500到2500(4000,效率62.5%)
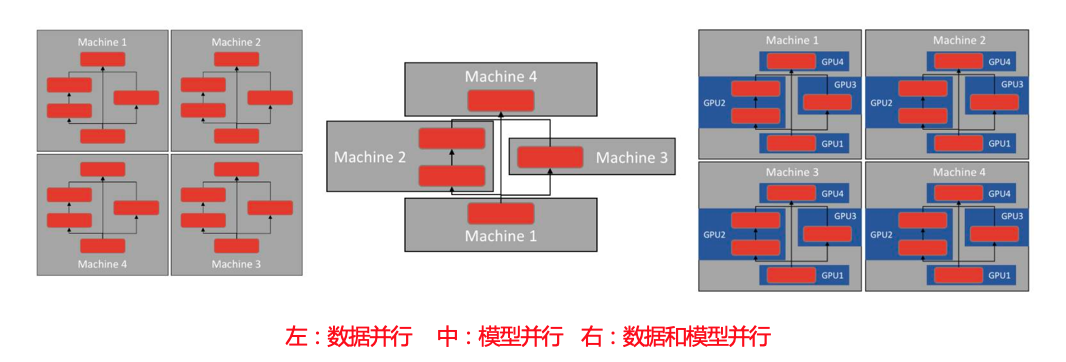
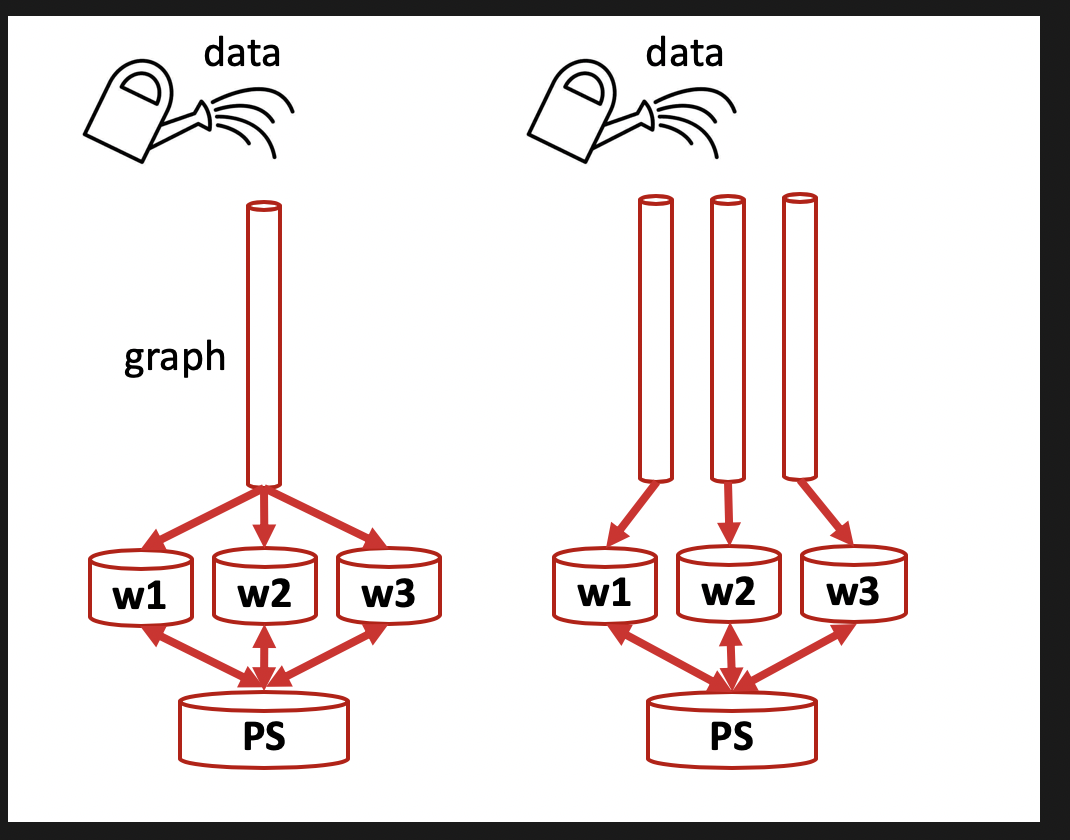
in-graph vs. between-graph
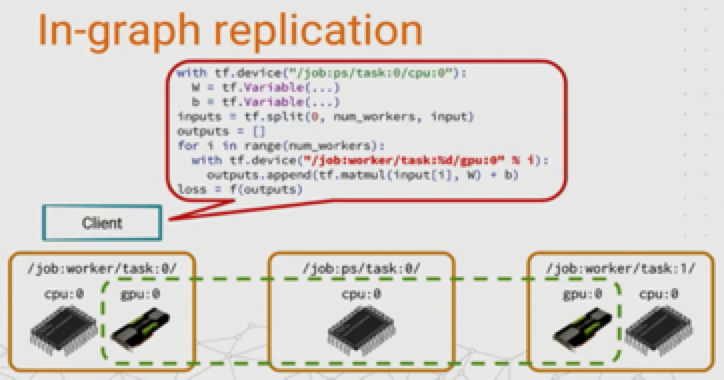
in-graph replication 图内复制
只存在一个Client进程,这个Client只创建一个Session,这个Session只构建一个图,并将模型计算复制到各个worker节点,如果 worker 节点及设备过多,计算图过大会导致性能下降;并且只构建一个 client,数据分发的效率以及整体容错性都不好。
between-graph replication 图间复制
每个worker节点都有各自的client,它们构建相同的计算图,然后把模型参数推送到ps节点上,多个worker共享ps上的参数,只需要更新参数,免除了数据分发环节,在规模较大的情况下,相比 in-graph 提高了训练并行效率和容错性。
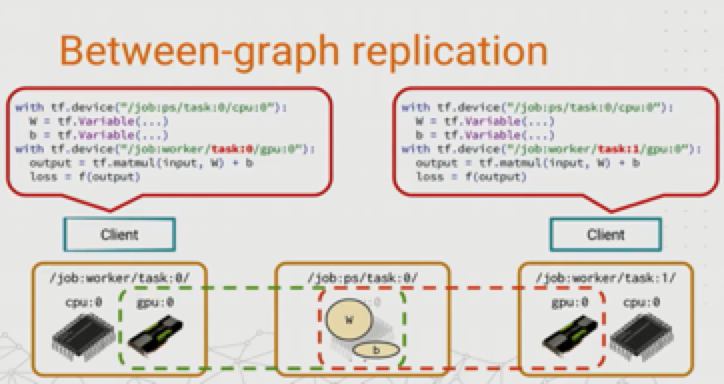
图内复制与图间复制的比较示意图:
Ring-allreduce 架构
Ring-allreduce介绍
-
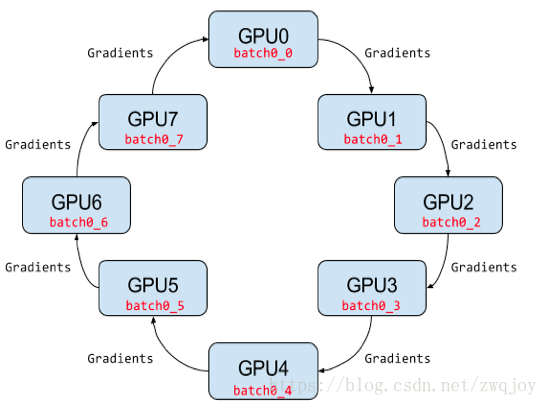
集群拓扑结构
GPU 集群被组织成一个逻辑环
每个 GPU 有一个左邻居、一个右邻居
每个 GPU 只从左邻居接受数据、并发送数据给右邻居
-
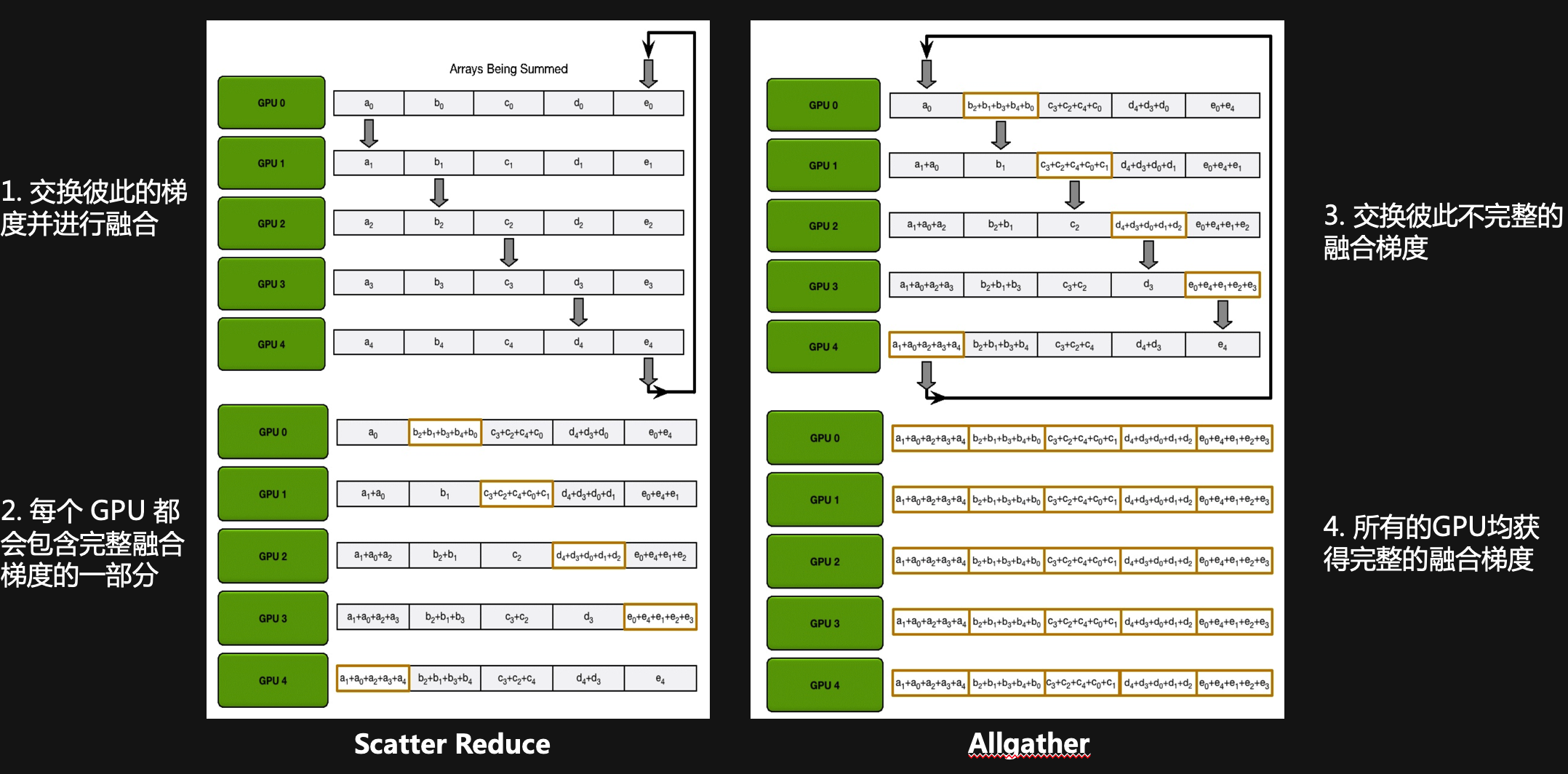
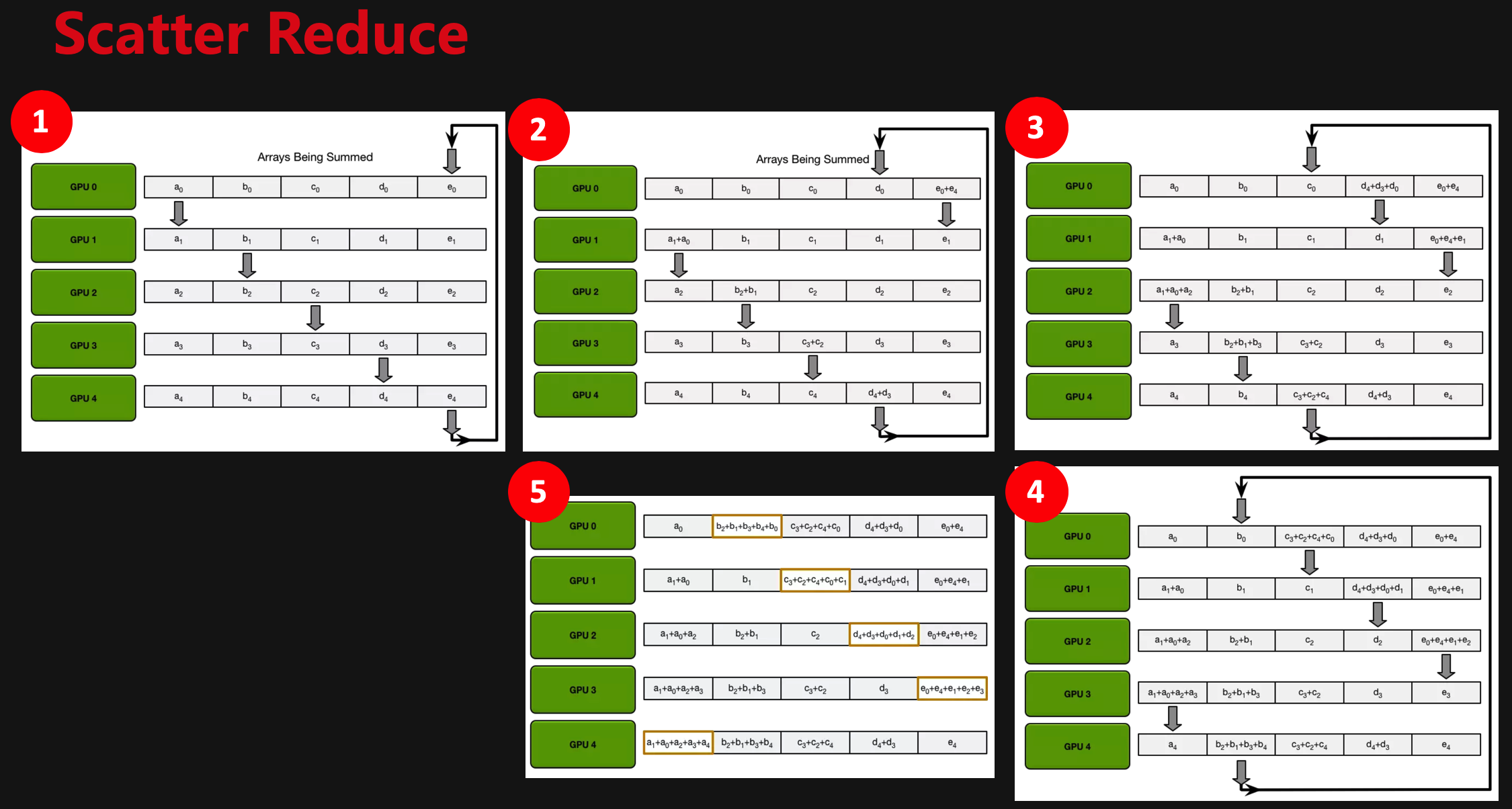
梯度融合
Scatter Reduce:GPU 会逐步交换彼此的梯度并进行融合,最后每个 GPU 都会包含完整融合梯度的一部
Allgather:GPU 会逐步交换彼此不完整的融合梯度,最后所有 GPU 都会得到完整的融合梯度
Ring-allreduce原理
Ring-allreduce优势
-
随GPU数量增多,通信成本恒定
① 一般情况下,系统中多GPU间参数同步的通信成本增加
单个GPU必须从所有GPU接收所有参数,并将所有参数发送到所有GPU,系统中的GPU越多,通信成本就越高。
② 使用Ring-allreduce,通信成本不随 GPU 数量增长而增长,系统拥有理论上的线性加速能力
N 是 GPU 数量,K 是同步的总数据大小(比如模型参数量)
每个 GPU 在Scatter Reduce 阶段,分发N-1 次数据
每个 GPU 在allgather 阶段,分发N-1 次数据
每个 GPU 每次发送 K/N 大小数据块
传输到每个GPU的数据总量(Data Transferred)=2(N−1)*K/N = (2(N−1)/N)*K ~= 2K
即随着 GPU 数量 N 增加,总传输量恒定
③ 举例
300million 参数也就是 1.2Gb 数据量,因此每个GPU必须发送和接收大约2.4Gb 数据, 假设网络使用 GPUDirect RDMA + InfiniBand,GPUDirect RDMA 带宽约为10Gb/s;InfiniBand 带宽约为 6Gb/s, 所以通信瓶颈在 InfiniBand 。(2.4Gb)/(6.0Gb/s) ≈ 400ms,也就是每轮迭代需要 400 ms 做参数同步, 这 400ms 的参数数据同步时间是恒定的,不随 GPU 数量增加而增加。
-
随GPU数量增多,样本处理量线性增大
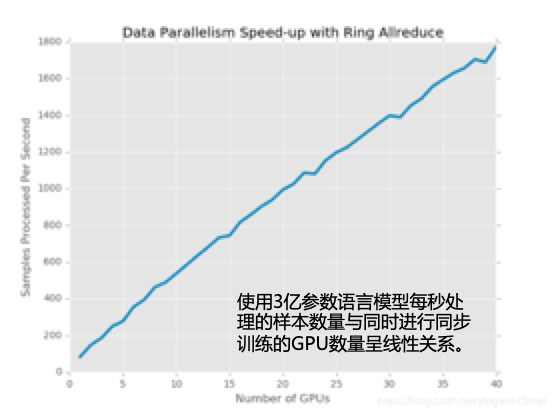
GPUs从5到40(8倍),数据处理速度从300到1800(2400,效率75%)
Horovod架构
特点
- 是 Uber 开源基于ring-allreduce的分布式深度学习框架
- 具备更快的数据处理时效
- 可以实现接近 0.9x 的加速比
- Only does synchronized parameter update
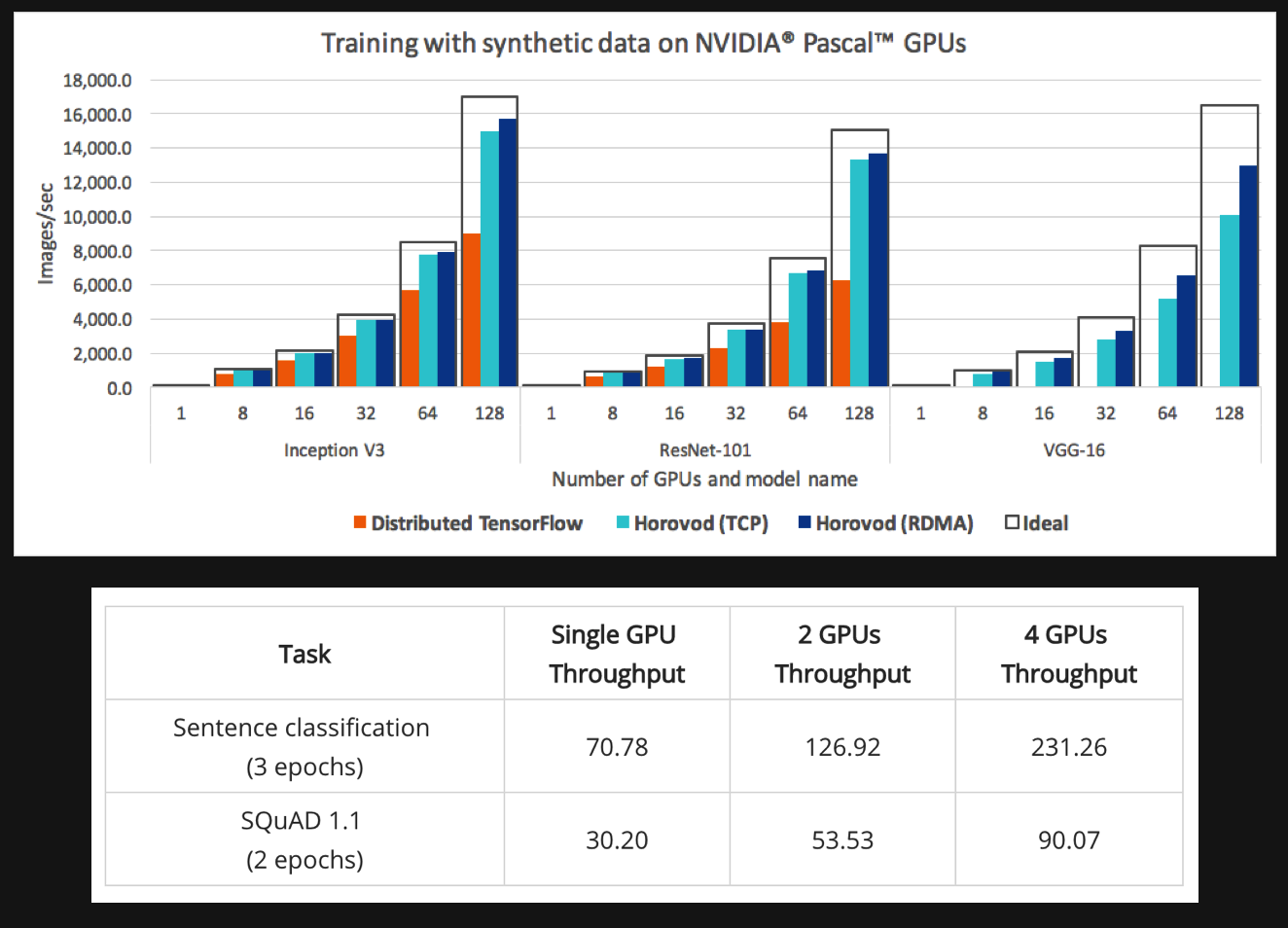
BERT Multi-GPU with horovod
https://lambdalabs.com/blog/bert-multi-gpu-implementation-using-tensorflow-and-horovod-with-code/