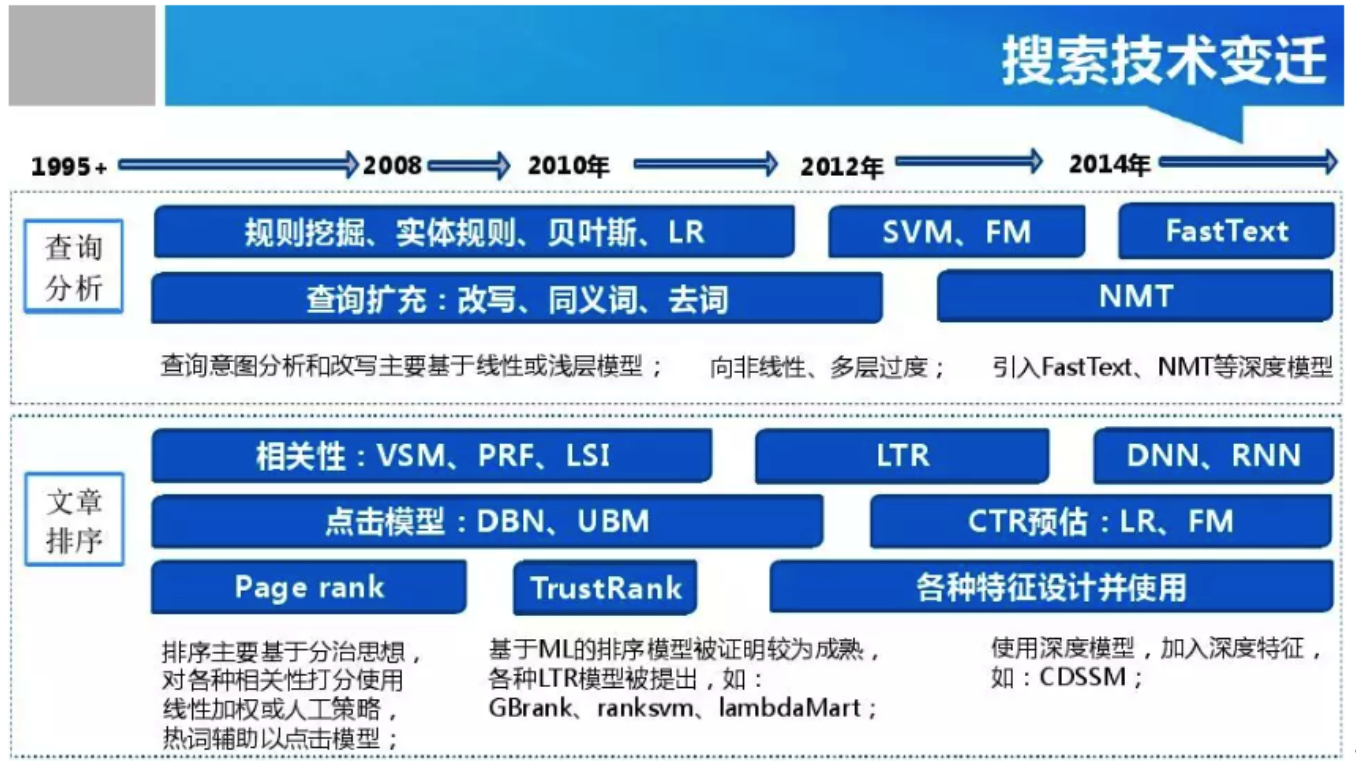
三种技术变迁和比较
常见的排序算法LTR(Learning to rank),将学习任务分为三种策略,即pointwise,pairwise,Listwise三类其
pointwise将其转化为多类分类或者回归问题
pairwise将其转化为pair分类问题
Listwise为对查询下的一整个候选集作为学习目标,三者的区别在于loss不同。
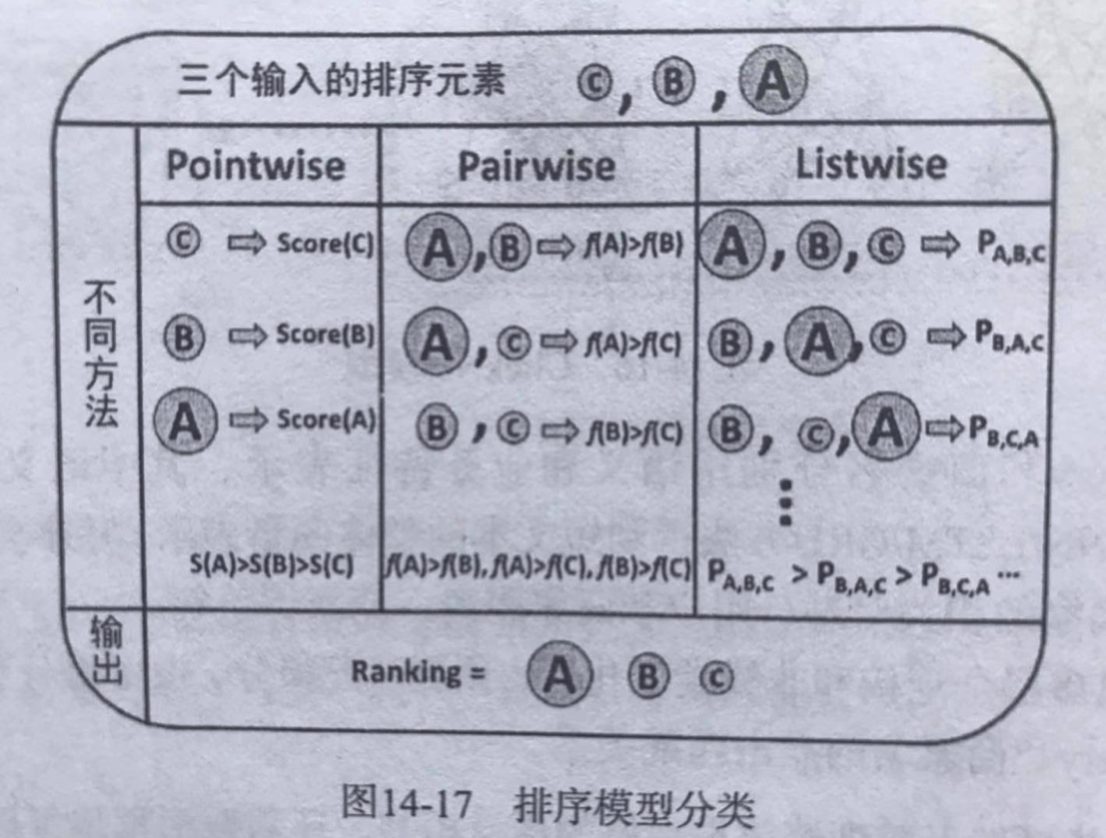
Pointwise
将训练集里每一个文档当做一个训练实例,直接预测query与doc之间的相关程度(或几档不同相关程度),即使用传统的机器学习方法对给定查询下反馈结果的相关度进行学习,学习的是全局的相关性,并不对先后顺序的优劣做惩罚,比如LR、GBDT、xgboost。其中,CTR预估相关策略也属于Pointwise的一种。
Pairwise
将同一个査询的搜索结果里任意两个文档对作为一个训练实例,如果列表先后排序为a,b,c,但其中只有b被点击了,则a>b这一对会被构建成负样本,b>c这一对会被构建成正样本,即学习的是不同查询结果对的前后顺序。常用方法:SVM Rank、RankNet(2007)、RankBoost(2003) 。

缺陷:
文档对方法考虑了两个文档对的相对先后顺序,却没有考虑文档出现在搜索列表中的位置,排在搜索结果前面的文档更为重要,如果靠前的文档出现判断错误,代价明显高于排在后面的文档(比如LambdaRank中使用DCG解决)
同时不同的査询,其相关文档数量差异很大,所以转换为文档对之后,有的查询对能有几百个对应的文档对,而有的查询只有十几个对应的文档对,这对机器学习系统的效果评价造成困难(比如LambdaRank中使用NDCG解决)
Listwise
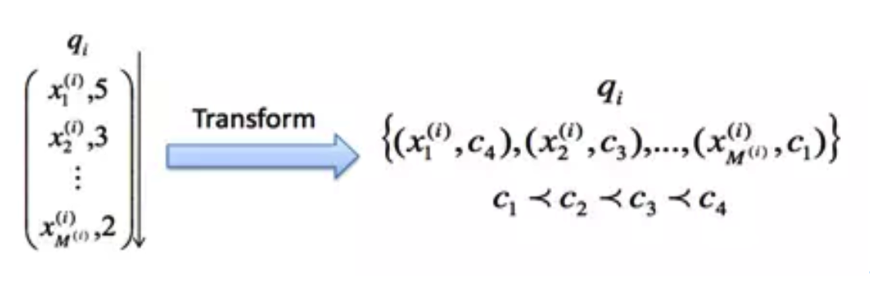
Pointwise方法将训练集里每一个文档当做一个训练实例,Pairwise方法将同一个査询的搜索结果里任意两个文档对作为一个训练实例,Listwise方法与上述两种方法都不同,Listwise方法直接考虑整体序列,将每一个查询对应的所有搜索结果列表整体作为一个训练实例,针对Ranking评价指标进行优化,比如常用的MAP, NDCG。常用的ListWise方法有:LambdaRank、AdaRank、SoftRank、LambdaMART。
几种典型LRT算法
RankNet
RankNet是一种经典的Pairwise的排序学习方法,是典型的前向神经网络排序模型。
假设文档A, B的特征分别为xi, xj,RankNet使用神经网络来训练模型,f(xi)是神经网络的输出,另oi=f(xi),oj=f(xj),则oij=oi-oj,文档对<A, B>的RankNet预测概率为:
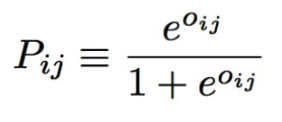
如果文档A比文档B和查询q更加相关, 则目标概率PAB=1,如果文档B比文档A更相关, 目标概率PAB=0,如果A和B同样相关, 则PAB=0.5,有了模型输出的概率Pij和目标概率PAB,我们使用交叉熵来作为训练的损失函数(如下),并梯度下降来优化损失函数。
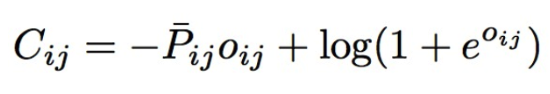
Pair-wise error:表示一个排列中,随机抽查任意两个item,一共有 Cn2 种可能的组合,如果这两个item的之间的相对排序错误,error值加1,并没有考虑位置的权重(比如排序靠前的错了会比排序靠后的错了,有更大的error),RankNet交叉熵优化的目标也是类似的,没有考虑位置权重。例如,对某个Query,和它相关的文章有两个,记为 (Q,[D1,D2]):
如果模型 f(⋅) 对此Query返回的n条结果中,D1,D2 分别位于前两位,则pair-wise error就为0;
如果模型 f(⋅) 对此Query返回的n条结果中,D1,D2 分别位于第1位和第n位,则pair-wise error为n-2;
如果模型 f(⋅) 对此Query返回的n条结果中,D1,D2 分别位于第2和第3位,则pair-wise error为2;
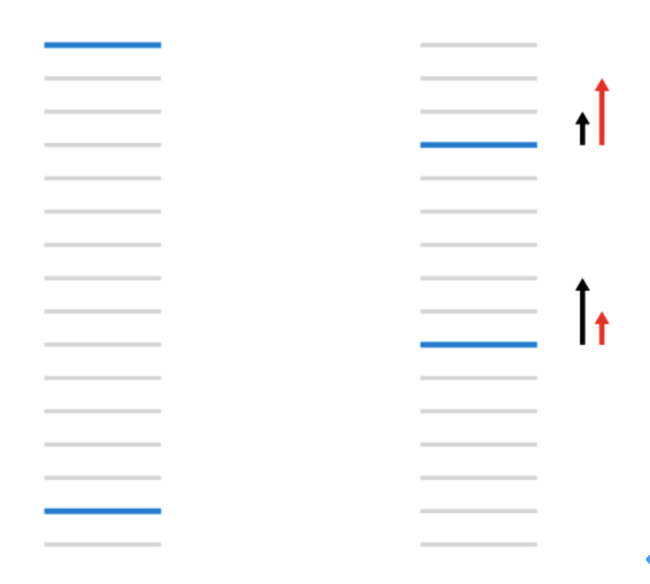
因此,针对如下排序情形,左边pair-wise error=15-2=13,右边pair-wise error=(4-1)+(10-2)=11,因此目标会朝着右边的趋势进行优化,损失虽然减少了,但右边并不是我们期望的排序优化趋势(黑色箭头),我们希望排序靠前的依然保持靠前,排序靠后的逐渐向上提升(红色箭头),因此提出了LambdaRank方法。
LambdaRank
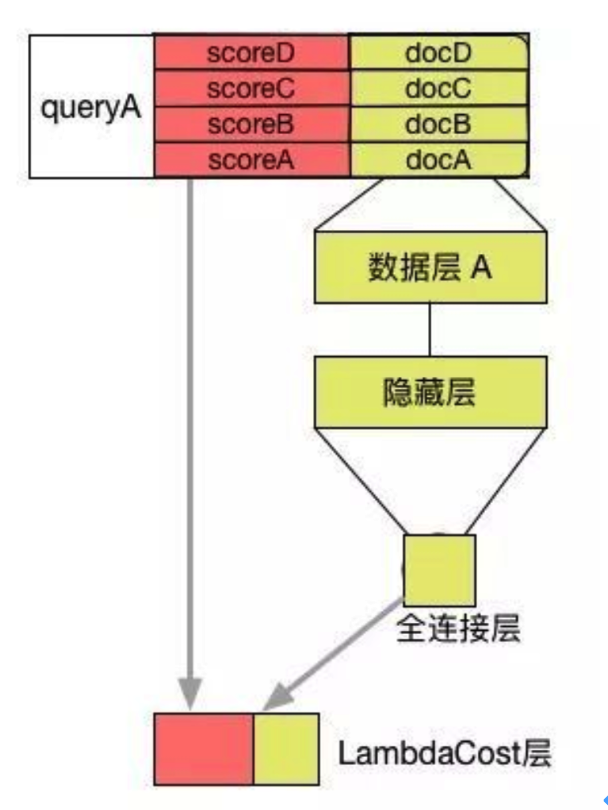
LambdaRank是Listwise的排序方法,是在RankNet模型的基础上改进而来,更关注位置靠前的优质查询结果排序位置的提升。一个查询得到的结果文档列表作为一条样本输入到网络中,替换RankCost为LambdaCost层,其他结构与RankNet相同。
LambdaCost层 :直接定义的了损失函数的梯度λ,也就是Lambda梯度。
Lambda梯度由两部分相乘得到:
(1) RankNet中交叉熵概率损失函数的梯度(即交叉熵损失函数的一阶导数);
(2) 交换Ui,Uj位置后IR评价指标Z的差值,Z可以是NDCG、ERR、MRR、MAP等IR评价指标。
损失函数的梯度代表了文档下一次迭代优化的方向和强度,由于引入了IR评价指标,Lambda梯度更关注位置靠前的优质文档的排序位置的提升,有效的避免了下调位置靠前优质文档的位置这种情况的发生。LambdaRank相比RankNet的优势在于考虑了评价指标,直接对问题求解,所以效果更好。
NDCG评价指标
累计增益(Cumulative Gain,CG)
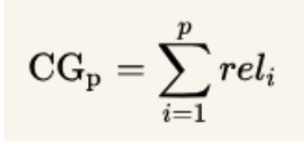
reli代表i这个位置上的相关度。举例:假设搜索“篮球”结果,最理想的结果是:B1、B2、B3,而出现的结果是 B3、B1、B2的话,CG的值是没有变化的,因此需要下面的DCG。
折损累计增益(Discounted Cumulative Gain,DCG)
就是在每一个CG的结果上处以一个折损值,目的让排名越靠前的结果越能影响最后的结果。假设排序越往后,价值越低,到第i个位置的时候,它的价值是 1/log2(i+1),那么第i个结果产生的效益就是 reli * 1/log2(i+1),所以:
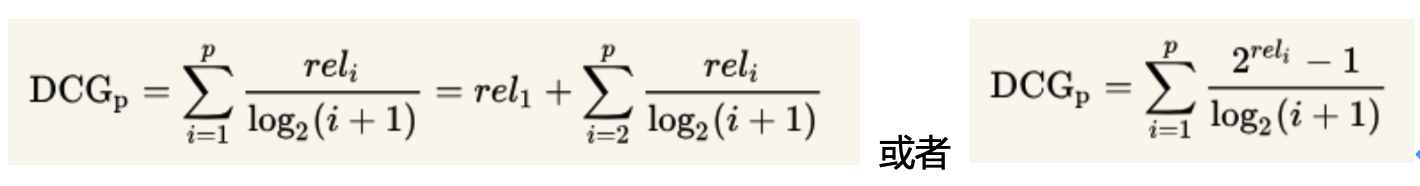
归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)
由于搜索结果随着检索词的不同,返回的数量是不一致的,而DCG是一个累加的值,没法针对两个不同的搜索结果进行比较,因此需要归一化处理,这里是除以IDCG(IDCG为理想排序下的最大DCG值)。
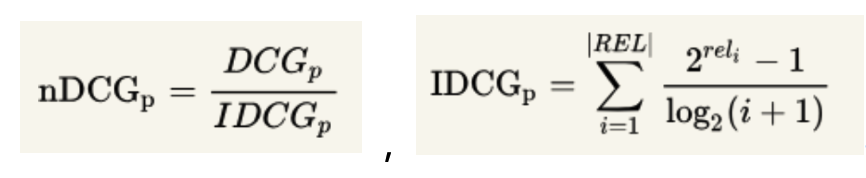
主要体现2个思想:
高关联度的结果比一般关联度的结果更影响最终的指标得分
有高关联度的结果出现在更靠前的位置的时候,指标会越高
NDCG举例:
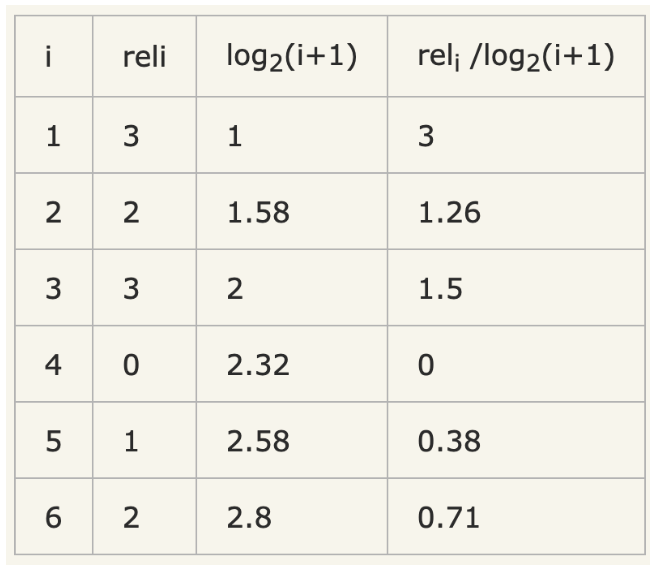
假设搜索出6个结果,其相关性分数分别是 3、2、3、0、1、2,那么 CG = 3+2+3+0+1+2=11,可以看到CG只是对相关的分数进行了一个关联的打分,并没有召回的所在位置对排序结果评分对影响。
而DCG = 3+1.26+1.5+0+0.38+0.71 = 6.86,考虑了排名前后的位置重要性。
计算NDCG,需要先计算IDCG,假如我们实际召回了8个物品,除了上面的6个,还有两个结果,假设第7个相关性为3,第8个相关性为0。那么在理想情况下的相关性分数排序应该是:3、3、3、2、2、1、0、0。计算IDCG@6,如下:
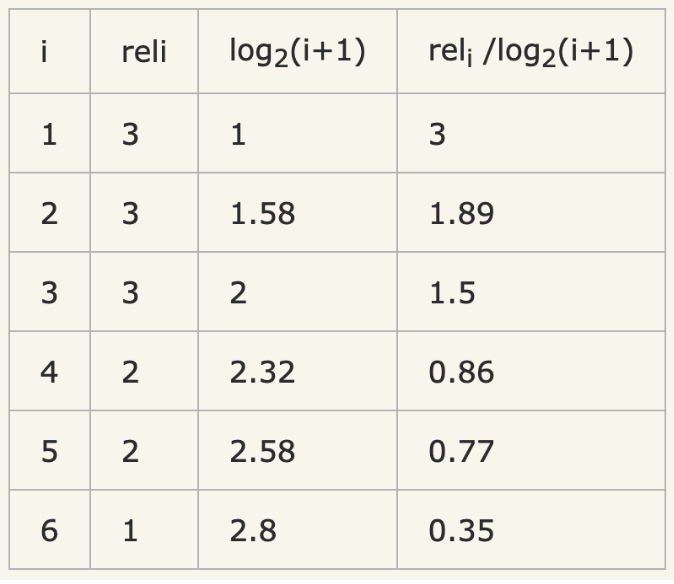
所以,IDCG = 3+1.89+1.5+0.86+0.77+0.35 = 8.37
最终, NDCG@6 = 6.86/8.37 = 81.96%,也即搜索出的6个结果排名的NDCG得分为81.96%。
LambdaRank
LambdaRank也是Listwise的排序方法,只是在GBDT的过程中做了一个很小的修改(MART也就是GBDT),即将原始GBDT通过「残差」最小化计算梯度的方式,直接修改为使用Lambda梯度,Lambda梯度的物理含义是一个待排序文档下一次迭代应该排序的方向。
RankLib实现
是一套优秀的LTR领域的开源实现,包括Pointwise、Pairwise以及Listwise的模型实现。
参考:
https://www.cnblogs.com/by-dream/p/9403984.html
https://www.jianshu.com/p/aab1bf1307fd
https://www.jianshu.com/p/3c5c1ea7d836