Word2vec是一种词嵌入模型。
句子需要先进行分词,而后将每词表示成一个固定长度的向量。假设词库大小为N,词向量长度为L,则通过语料库学习到这个W=N*L矩阵的内容,也就是该预料库下每个词的向量表示。
Word2vec考虑词之间共出现的概率,但是未考虑语义信息。有了词的向量表示,后续就可以衔接其他分类模型,解决文本分类或其他问题了。
在学习该词向量矩阵W时,有2种模式:CBOW(填空式)、skip-gram(造句式),如下:
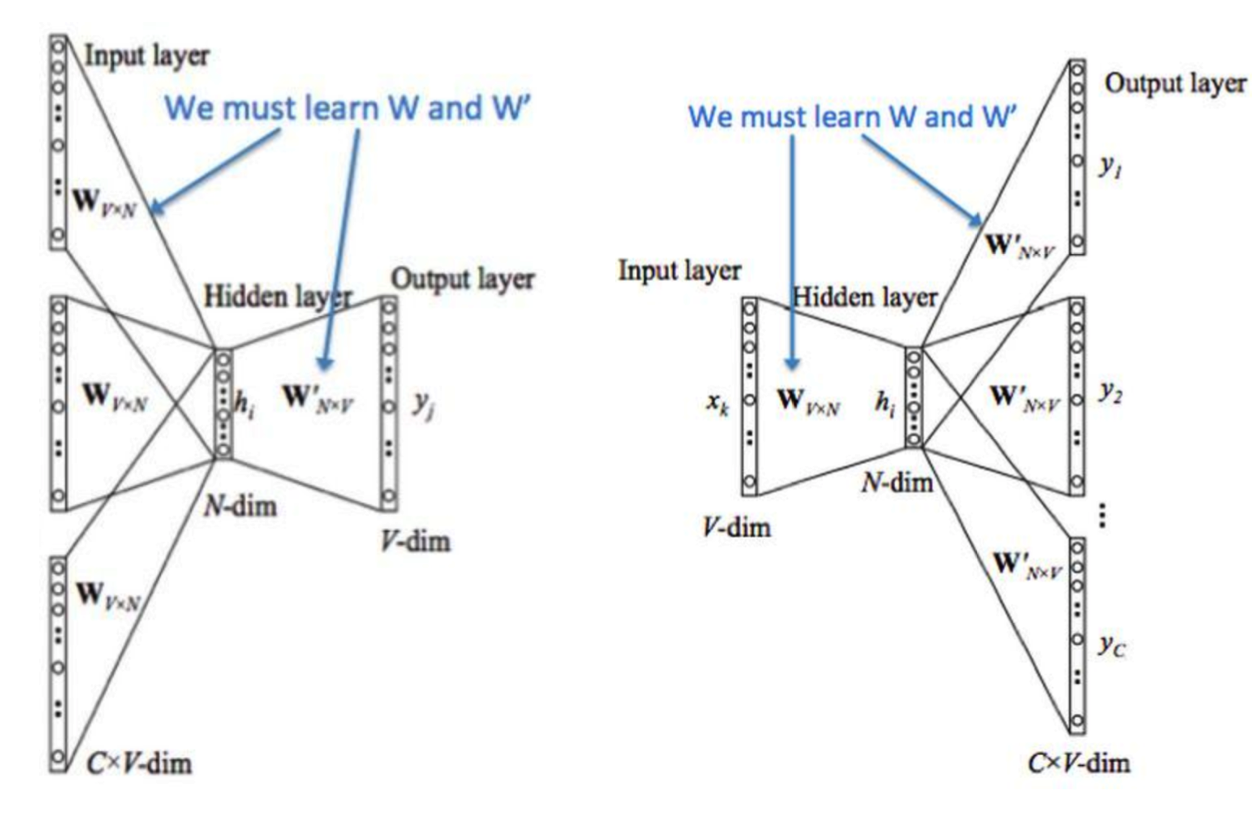
CBOW词向量学习方法
-
将预料库进行分词,而后构建所有词语的向量矩阵W,行为词库大小V,列为词向量长度N,W需进行随机初始化
-
针对词库中每一条数据(分词后)进行CBOW或Skip-gram任务,比如以窗口划分的方式,使用周围几个词预测某个词出现的概率
-
从词向量矩阵W中查找到该条数据所有相关的词向量(one-hot方式),假设有s个词向量,将这s个词向量进行汇总操作(加和/平均),使其合并为一个向量,s大小变为1*N
-
隐藏层矩阵是W’,再使用sW’,获得1V的向量,再经过softmax,即预测词库中所有词的概率,出现最大概率的词,即为当前预测的词
-
经过多个迭代的反向传播,计算W和W’矩阵,W即为具备语料库信息的词向量矩阵
-
而后,可以从W中提取相关向量,进行文本分类等其他操作
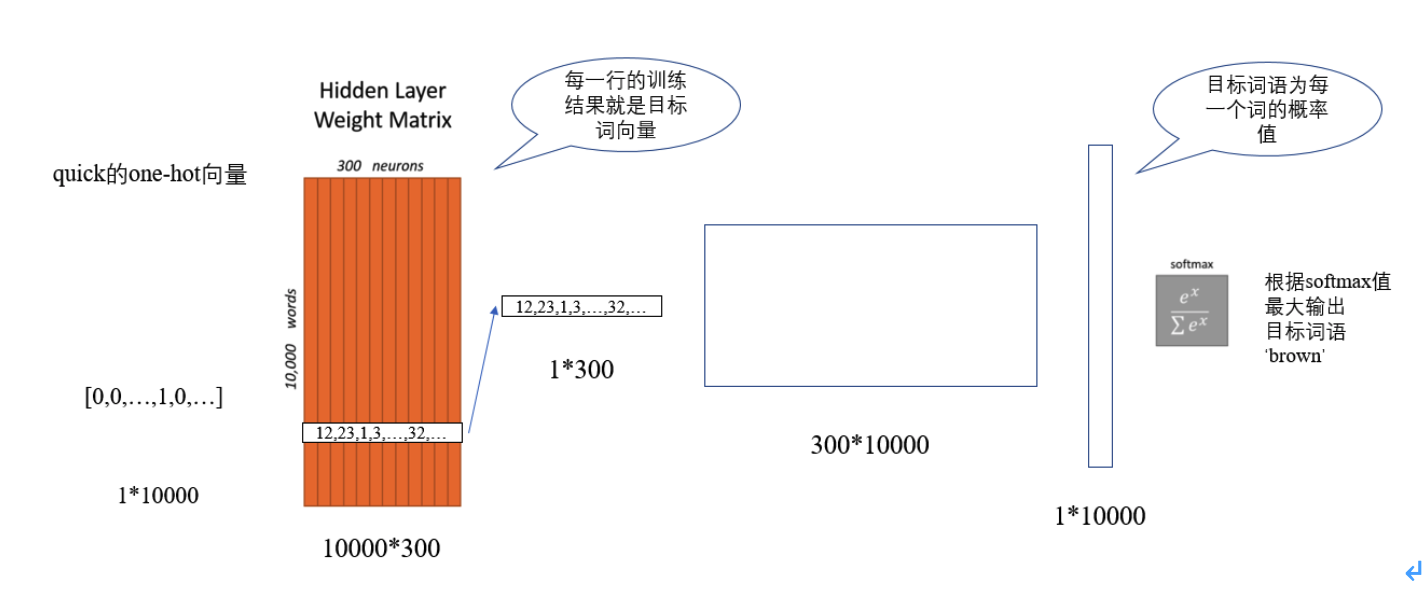
Skip-gram词向量学习方法
与CBOW类似,但softmax之后取topn的预测结果,n为预测当前词上下文窗口长度内词的个数。
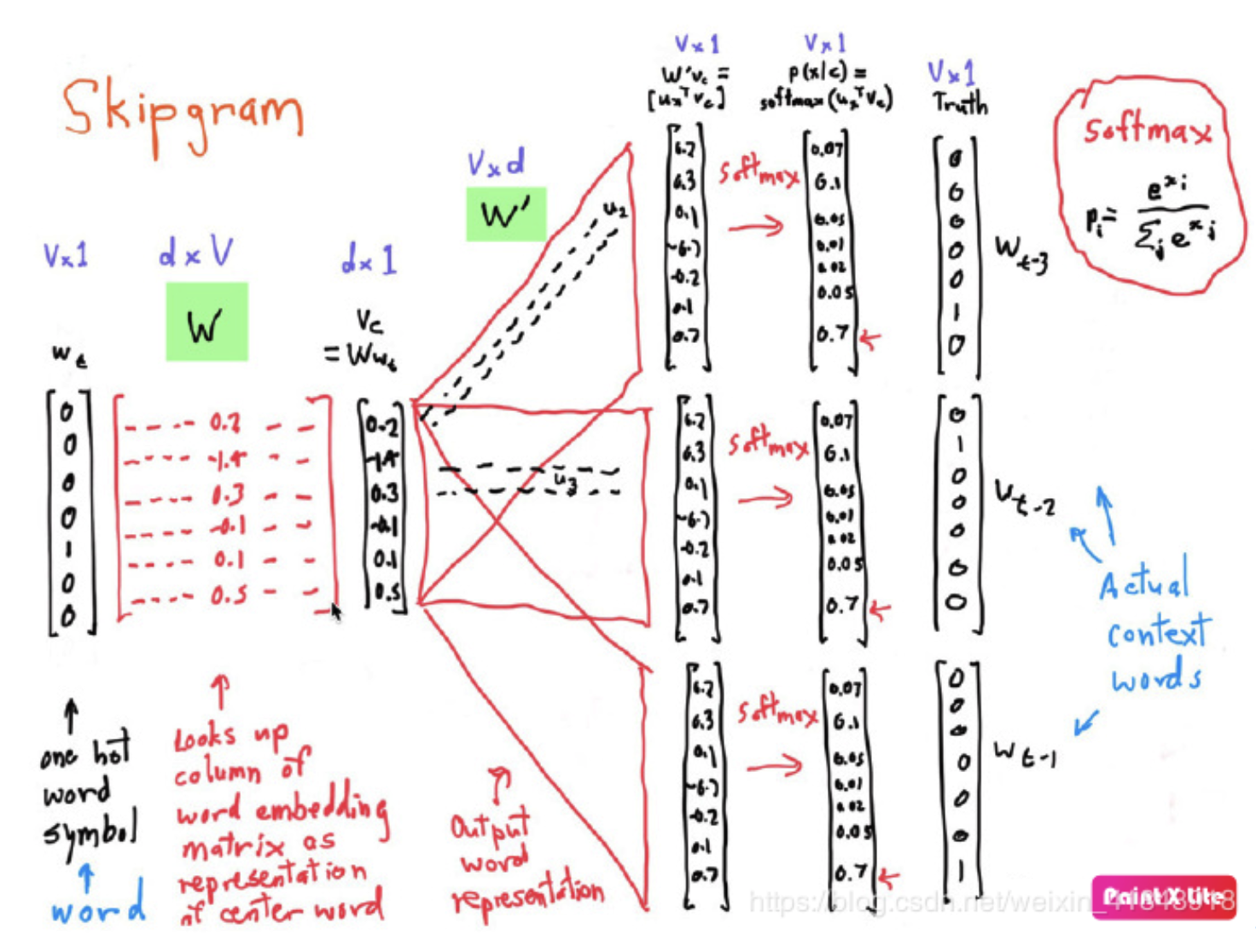
CBOW与Skip-gram比较
简单的来说,cbow会将context word 加起来,在遇到生僻词是,预测效果将会大大降低,而skip-gram则会预测生僻字的使用环境。因此,cbow比skip-gram训练快,skip-gram比cbow更好地处理生僻字(出现频率低的字)。
具体如下:
-
CBOW是用周围词预测中心词,训练过程中其实是在从output的loss学习周围词的信息,也就是embedding,由于中间层进行average,一共预测V(vocab size)次就够了。
-
skipgram是用中心词预测周围词,预测的时候是一对word pair,等于对每一个中心词都有K个词作为output,对于一个词的预测有K次,所以能够更有效的从context中学习信息,但是总共预测K*V词。
因此,skip gram的训练时间更长,但是对于一些低频词,在CBOW中的学习效果就不如skipgram。
Word2vec的优化
在经过softmax时,如果词库量比较大,可以采取2种方式加快训练速度:
层次softmax
基于哈夫曼树,将原始N分类问题,转化成log(N)个二分类问题,树中每个节点表示一个softmax(即一个权值),树中每个分支的所有节点概率乘积,用于计算某个词的概率,越是出现频率高的词,路径越短。
Softmax计算过程中,预测每个词出现概率的时间复杂度为N,层次softmax把N个样本构建成二叉树后,使得时间复杂度变为树的深度log(N)
2^k-1=N,即节点数目k=log2(N)+1,即计算的时间复杂度由N变为log(N)
高频词抽样+负采样
主旨:去除长尾词、针对语料库高频词进行降采样
高频词抽样
少训练没有区分度的高频词,即基于语料库中的词频,进行抽样,越是高频词,抽样概率越小。计算高频词抽样率P(w)时,有个认为设定的阈值t(即为gensim中的“sample=0.001”),t越大,不同频率词的采样差异越大。

负采样
word2vec中,对于每个词的预测,都会更新全体词对应的W参数矩阵,计算量很大,如果改为与目标词周围的词(即正样本)和少数无关词(即负样本)对应的参数进行更新,则可大大降低参数计算,选取的负样本数量即为参数negative=5。
负样本选择:基于词表中出现的概率,出现概率越高,被选作负样本的概率越高(与高频词抽样相反),负样本抽样率P(w)如下:

Gensim中word2vec参数
默认用了CBOW模型,采用“高频词抽样+ 负采样”进行优化,参数如下:
上下文窗口大小:window=5
忽略低频次term:min_count=5
语言模型是用CBOW还是skip-gram? sg=0 是CBOW
优化方法是用层次softmax还是负采样? hs=0 是负采样
负采样样本数: negative=5 (一般设为5-20)
负采样采样概率的平滑指数:ns_exponent=0.75
高频词抽样的阈值 sample=0.001
参数表
sentences:可以是一个list,对于大语料集,建议使用BrownCorpus,Text8Corpus或LineSentence构建。 sg: 用于设置训练算法,默认为0,对应CBOW算法(填空);sg=1则采用skip-gram算法(造句)。 size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。 window:表示当前词与预测词在一个句子中的最大距离是多少 alpha: 是学习速率 seed:用于随机数发生器。与初始化词向量有关。 min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5 max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。 sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5) workers: 参数控制训练的并行数。 hs: 如果为1则会采用hierarchical softmax技巧。如果设置为0(defaut),则negative sampling会被使用。 negative: 如果>0,则会采用negativesamping,用于设置多少个noise words cbow_mean: 如果为0,则采用上下文词向量的和,如果为1(defaut)则采用均值。只有使用CBOW的时候才起作用。 hashfxn: hash函数来初始化权重。默认使用python的hash函数 iter: 迭代次数,默认为5 trim_rule: 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受()并返回RU·E_DISCARD,uti·s.RU·E_KEEP或者uti·s.RU·E_DEFAU·T的函数。 sorted_vocab: 如果为1(defaut),则在分配word index 的时候会先对单词基于频率降序排序。 batch_words:每一批的传递给线程的单词的数量,默认为10000
参考:
https://blog.csdn.net/weixin_41843918/article/details/90312339
https://www.cnblogs.com/liyuxia713/p/11185028.html
http://qiancy.com/2016/08/17/word2vec-hierarchical-softmax/
https://blog.csdn.net/chinwuforwork/article/details/85180138